CUDA programming 2
More details of the basics, the matrix multiply example is carefully analysed and a optimised version is coded.
All the pics and contents are not original. The contents of the whole series are mainly collected from:
Build-ins and functions
Declarations
| Executed on the: | Only callable from the | |
|---|---|---|
__global__ |
device | host |
__device__ |
device | device |
__host__ |
host | host |
note:
__global__and__device__can declare one function__host__ __device__ func () { // ………… }__global__function must returnvoid__device__inline function by default, might have been changed recentlyRecursion allowed for some device function, be carefull
No static parameters
No
malloc(), memory will run out soon if all the threads usemalloccareful using pointers
Vector datatypes
Including:
char[1-4], uchar[1-4], short[1-4], ushort[1-4], int[1-4], uint[1-4], longlong[1-4], ulonglong[1-4], float[1-4], double1, double2.
Instantantiate with function make_<type name>:
int2 i2 = ake_int2(1,2);
float4 f4 = make_floate4(1.0f, 2.0f, 3.0f, 4.0f);Reference with .x, .y, .z, .w :
int2 i2 = ake_int2(1,2);
int x = i2.x;
int y = i2.y;Math
Including basic build-in math functions such as:
sqrt, rsqrt, exp, log, sin, cos, tan, sincos, asin, acos, atan2, asin, acos, atan2, trunc, ceil, floor...
Besides, there is another type of math functions: Intrinsic functions:
- Device only
- 10x faster but lower precision
- Prefixed with
__
- names as:
__exp,__log,__sin,__pow...
Threads Synchronizition
Recall Thread hierarchy
Recall CUDA memory hierarchy in GPU, the thread can be index with blockId and threadId: (1D indexing for example)
int threadID = blockIdx.x * blockDim.x + threadIdx.x;
float x = input[threadID];
float y = func(x);
output[threadID] = y;Synchronizing threads
Threads in the same block (not gird) can be synchronized with function __syncthreads(), this function create a barrier:
Mds[i] = Md[j];
__syncthreads();
func(Mds[i], Mds[i+1]);- need similar execution time for each thread
- block synchronize is a compromise because global synchronization costs too much.
Problem of synchronizing
synchronizing actually breaks the parallelization, and more severely, it can leads to thread deadlock, such as below:
if (someFunc())
{
__syncthreads();
}
else:
{
__syncthreads();
}no syncthreads in branches !
Scheduling model
Example
Take a old G80 as an example:
- 16 SMs, 8 SPs per SM
- 128 SPs in total
- up to768 treads on a SM, not all been executed
- 12288 threads in total, (on 16 SMs)
Warp
Warp is a logical concept, it represents a goup of threads in a block.
threadIndxs are concecutive.- if there are 64 threads run on the same block, a warp has 32 threads. So it has 2 warps, the
threadIndxare[0-31],[32-63].
- if there are 64 threads run on the same block, a warp has 32 threads. So it has 2 warps, the
- Basic unit of thread scheduling
- Run on the same SM (block)
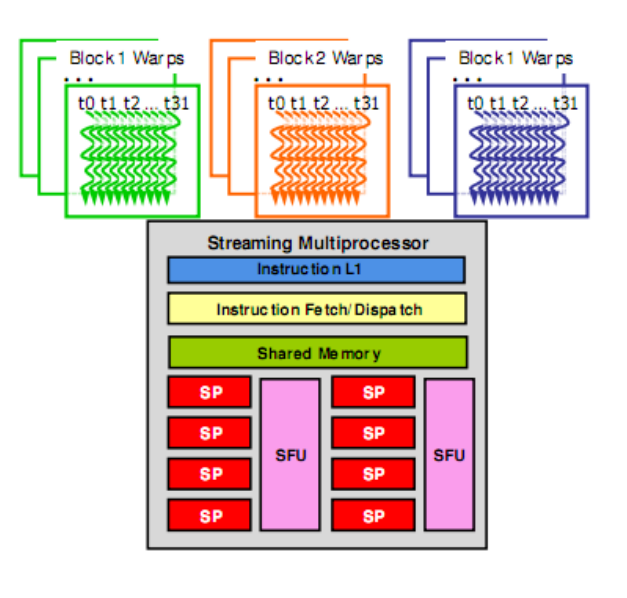
- Ant any time, only one of the warps is executed by SM.
- The threads in the same warp are sychronized in nuture, the instruction is the same as well.
- The not-running warps are saved in the context memory
- The warps whose next instruction hasits operands ready for consumptiona are sligible for execution.
- They can be switched (schedualed) as a click, with no overhead in order to hide latency.
Branches
Recall the branch divergence, it is also called warp divergence

In extreme, the performance will drop drastically, yet is has been highly optimised. And it is unessasary to worry about, except massive complicated branches exist, which is very rare.
Cycles
If More threads than SPs
In G80, there are 32 threads per warp but 8 SPs per SM. The num of thead in one warp is more than the number of SPs (ALUs). So the serial in warp is needed.
When an SM schedules a warp:
- Its instruction is ready
- 8 threads enter the SPs on the 1st cycle
- 8 more on the 2nd, 3rd, and 4th cycles
- Therefore, 4 cycles are required to dispatch a warp
In new archtecture, the number of SPs are way more than that of threads per warp.
Number of warps to hide latency
Example, a kernel has 1 global memory read (200 cycles) and 4 independent multiples/adds. How many warps are required to hide the memory latency in G80?
- Each warp has 4 MUL/ADDs, there are 16 cycles. Because 4 cycles in one wrap
- To conduct a global memory read, it has 200 cycles stall. We need to cover it by MUL/ADD cyckes.
- Cycles needed \(ceil(200/16) = 13\);
- 13 warps are needed for one block.
Memory model
Table
| Memory | Device | Host | Scope | Locality | Latency | Bandwidth | Note |
|---|---|---|---|---|---|---|---|
| registers | R/W | × | thread | On-chip | Short | *More register per thread, less thread per grid | |
| local | R/W | × | thread | global memory | Long | Automatic arrays | |
| shared | R/W | × | bock | on-chip | Short | *More memory per block, less block per grid. Full speed random access |
|
| global | R/W | R/W | grid | off-chip | Long 100 cycles | GT200 -150 GB/s, G80 – 86.4 GB/s | Up to 4 GB Random access causes performance hit |
| constant | R | R/W | grid | global memory (cached) | Short | High | Up to 64 KB When all threads access the same location |
* Increasing the number of registers used by a kernel , exceeding limit reduces threads by the block.
For example, there are 8K registers, up to \(768\) threads per SM. \(256\) threads per block so \(768/256\) 3 blocks on SM.
\(8K/768 = 10\) registers per thread.
If each thread uses 11 registers.
- only 2 blocks can fit the register number. So only \(2*256 = 512\) threads on SM. \(512*11 = 5.6K\) registers are used.
* For Shared Memory, the shared memory is \(16\)KB. \(8\) blocks per SM, then that's \(16/8=2\)KB per block.
If each block uses 5 KB, obly 3 blocks a SM can host.
* there is another Special Register used for build-in varibles, such as:
threadIdxblockIdxblockDimgridDim
Declaration
| Variable Declaration | Memory | Scope | Lifetime |
|---|---|---|---|
| Automatic variables other than arrays | register | thread | kernel |
| Automatic array variables | local | thread | kernel |
__shared__ int sharedVar; |
shared | block | kernel |
__device__ int globalVar; |
global | grid | application |
__constant__ int constantVar; |
constant | grid | application |
Global and constant variables:
Host can access with
cudaGetSymbolAddress()cudaGetSymbolSize()cudaMemcpyToSymbol()cudaMemcpyFromSymbol()
Constants is better (previously a must) be declared outside of a function body
__constant__ float constData[256]; // global scope
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
cudaMemcpyFromSymbol(data, constData, sizeof(data));Matrix multiply Again
Problems that Still Exist
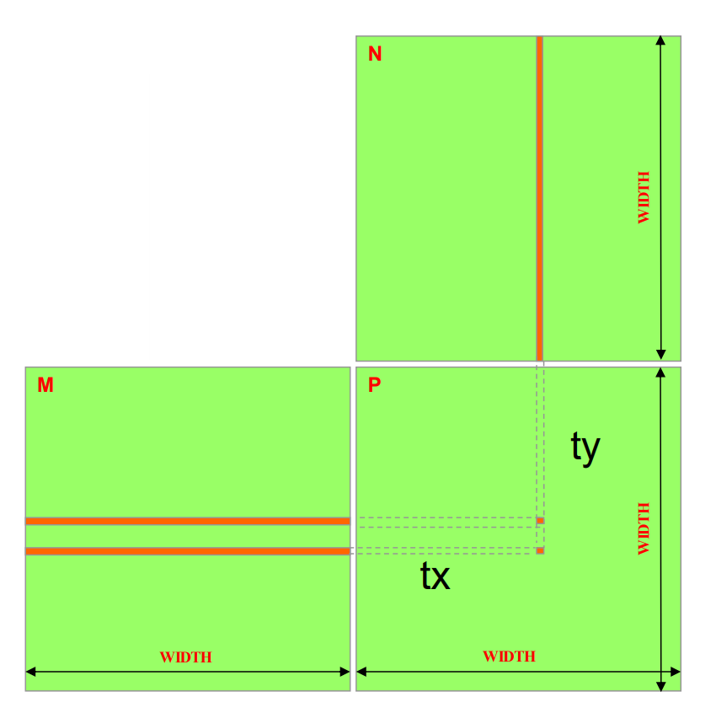
Recall the limitations of the code from last time:
- Limited matrix size
- Only uses one block
- G80 and GT200 – up to 512 threads per block
- Lots of global memory access
- two store-read and pre MUL-ADD
- with the data in the same column, the same colmn data of N matrix is readed again and again. Same for the data in the same row.
- Its better if the colume data can be calculated with only one-time read of the column N.
Solve problems
Remove size limitation
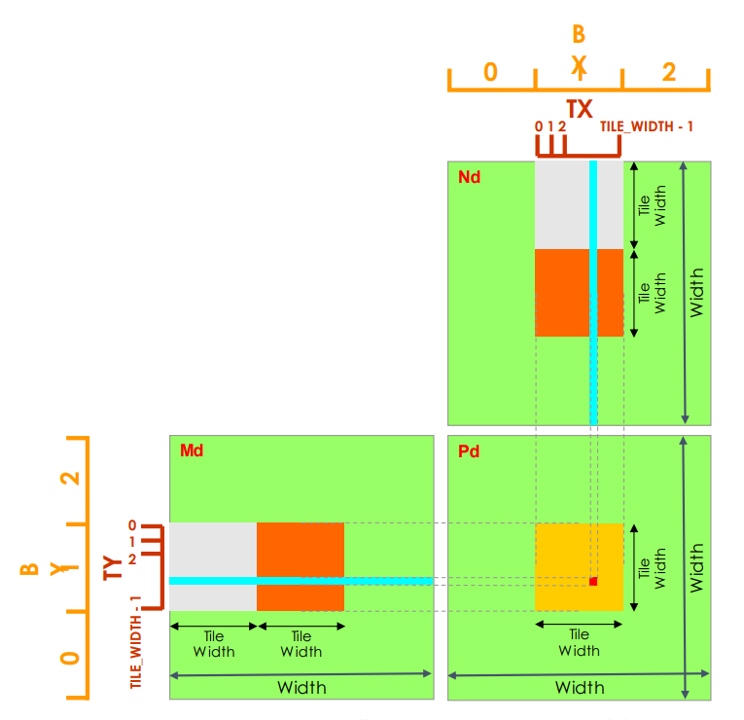
- Divide the matrix into tiles, assign each tile to a block.
- Use threadIdx and blockIdx for indexing.
- Able to use multiple blocks.
Implement the kernel
__global__ void MatrixMultiplyKernel(const float* devM, const float* devN,
float* devP, const int width)
{
// Calculate row and col index of P and M
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
// Initialize accumulator to 0
float pValue = 0;
// Multiply and add
for (int k = 0; k < width; k++)
{
float m = devM[row * width + k];
float n = devN[k * width + col];
pValue += m * n;
}
// Write value to device memory - each thread has unique index to write to
devP[row * width + col] = pValue;
}Invoke the kernel
void MatrixMultiplyOnDevice(float* hostP,
const float* hostM, const float* hostN, const int width)
{
int sizeInBytes = width * width * sizeof(float);
float *devM, *devN, *devP;
// Allocate M and N on device
cudaMalloc((void**)&devM, sizeInBytes);
cudaMalloc((void**)&devN, sizeInBytes);
// Allocate P
cudaMalloc((void**)&devP, sizeInBytes);
// Copy M and N from host to device
cudaMemcpy(devM, hostM, sizeInBytes, cudaMemcpyHostToDevice);
cudaMemcpy(devN, hostN, sizeInBytes, cudaMemcpyHostToDevice);
// Call the kernel here
// Setup thread/block execution configuration
dim3 dimBlocks(TILE_WIDTH, TILE_WIDTH);
dim3 dimGrid(WIDTH / TILE_WIDTH, WIDTH / TILE_WIDTH);
// Launch the kernel
MatrixMultiplyKernel<<<dimGrid, dimBlocks>>>(devM, devN, devP, width
// Copy P matrix from device to host
cudaMemcpy(hostP, devP, sizeInBytes, cudaMemcpyDeviceToHost);
// Free allocated memory
cudaFree(devM); cudaFree(devN); cudaFree(devP);
}global memory access
Limitation
Limited by global memory bandwidth
G80 peak GFLOPS: 346.5
Require 346.5*4 bytes = 1386 GB/s to achieve this
4 bytes for each float datatype
G80 memory bandwidth: 86.4 GB/s
- Limits code to 86.4/4 = 21.6 GFLOPS
- In practice, code runs at 15 GFLOPS, less than 1/2 of the peak performance!
Must drastically reduce global memory access
Solve
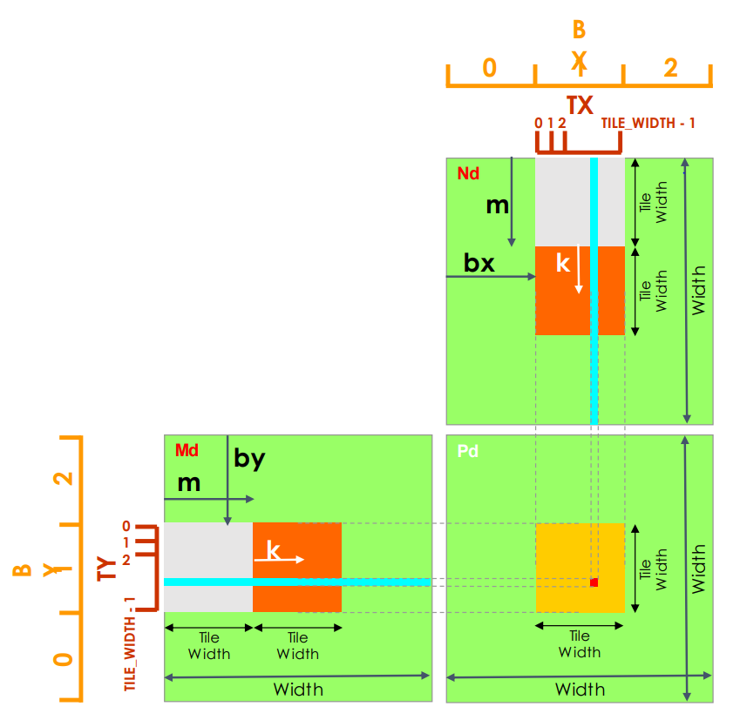
Becuase for matrix multiply, each input element is read by Width threads
We can use shared memory to reduce global memory bandwidth
Break kernel into phases
- Each phase accumulates Pd using a subset of Md and Nd Each phase accumulates Pd using a subset of Md and Nd
- Each phase has good data locality
__global__ void MatrixMultiplyKernel(const float* devM, const float* devN,
float* devP, const int width)
{
// Shared memory of M and N submatrices, size of tile width
__shared__ float sM[TILE_WIDTH][TILE_WIDTH];
__shared__ float sN[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int col = bx * TILE_WIDTH + bx;
int row = by * TILE_WIDTH + ty;
// Initialize accumulator to 0
float pValue = 0;
// Multiply and add
// m is index of current phase
// width / TILE_WIDTH is the number of phases
for (int m = 0; m < width / TILE_WIDTH; m++)
{
// Bring one element from each devM and devN into shared memory
sM[ty][tx] = devM[row * width + (m * TILE_WIDTH + tx)];
sN[ty][tx] = devN[col + (m * TILE_WIDTH + ty) * Width];
__syncthreads();
// Accumulate subset of dot product
for (int k = 0; k < TILE_WIDTH; ++k)
{
Pvalue += sM[ty][k] * sN[k][tx];
}
__synchthreads();
}
devP[row * width + col] = pValue;
}pick TILE_WIDTH
By exceeding the maximum number of threads/block
- G80 and GT200 – 512
- Fermi & newer – 1024
By exceeding the shared memory limitations
- G80: 16KB per SM and up to 8 blocks per SM
- 2KB per block
- 1KB for Nds and 1KB for Mds (16*16*4)
- TILE_WIDTH = 16
- A larger TILE_WIDTH will result in less blocks
Benefits
Reduces global memory access by a factor of TILE_WIDTH
- 16x16 tiles reduces by a factor of 16
G80
- Now global memory supports 21.6 * 16 = 345.6 GFLOPS
- Close to maximum of 346.5 GFLOPS
First-order Size Considerations
Each thread block should have many threads
TILE_WIDTH of 16 gives 16*16 = 256 threads
There should be many thread blocks
A 1024*1024 Pd gives 64*64 = 4096 Thread Blocks
Each thread block perform 2*256 = 512 float loads from global memory for 256 * (2*16) = 8192 mul/add operations.
Memory bandwidth no longer a limiting factor- Each thread block should have many threads
- TILE_WIDTH of 16 gives 16*16 = 256 threads
- There should be many thread blocks
- A 1024*1024 Pd gives 64*64 = 4096 Thread Blocks
- Each thread block perform 2*256 = 512 float loads from global memory for 256 * (2*16) = 8192 mul/add operations.
- Memory bandwidth no longer a limiting factor
Atomic functions
| arithmic operations | bit operations |
|---|---|
atomicAdd(); |
atomicAnd(); |
atomicSub(); |
atomicOr(); |
atomicMin(); |
atomicXor(); |
atomicExch(); |
|
atomicMin(); |
|
atomicMax(); |
|
atomicAdd(); |
|
atomicDec(); |
|
atomicCAS(); |
Atomic operations are operations which are performed without interference from any other threads. Atomic operations are often used to prevent race conditions which are common problems in mulithreaded applications.
For example, suppose you have two threads named A and B. Now suppose each thread wants to increase the value of memory location 0x1234 by one. Suppose the value at memory location 0x1234 is 5. If A and B both want to increase the value at location 0x1234 at the same time, each thread will first have to read the value. Depending on when the reads occur, it is possible that both A and B will read a value of 5. After adding a value of 1, both A and B will want to write 6 into the memory location, which is not correct! The value, 5, should have been increased twice (once by each thread), but instead, the value was only increased once! This is called a race condition, and can happen in any multi-threaded program if the programmer is not careful.
Atomic operations in CUDA generally work for both shared memory and global memory. Atomic operations in shared memory are generally used to prevent race conditions between different threads within the same thread block. Atomic operations in global memory are used to prevent race conditions between two different threads across the blocks.