CUDA Performance
The limits of performance and way of optimisation are introduced with examples, mostly memory optimisation and warp divergence.
One rule
Efficient data-parallel algorithms + Optimizations based on GPU Architecture = Maximum Performance
Memory Optimisation
Minimise CPU-GPU data transfer
The data transfer between CPU and GPU depends on PCIe bus. The
host <-> devicebandwidth are far lower than that ofglobal memory.8GB/s (PCIe x16 Gen2) vs 156GB/s & 515Ginst/s (C2050 (Fermi))
Minimise data transfer
Allocate, operating, free the intermediate variables directly on
deviceSometimes it isfaster to compute multiple times on GPU than compute one time on CPU with two data transfers.
- The cost by data transfer might be bigger than the multiple computational cost on GPU.
Directly transfer CPU code to GPU might not get a higher performance, if the data transfer is not optimised.
Transfering bigger data is better than smaller data. If the data < 80KB, the latency dominants the performance.
data transfer at the same time with the computation
double buffering, one for the data transfer and the other for the computation
The term double buffering is used for copying data between two buffers for direct memory access (DMA) transfers, not for enhancing performance, but to meet specific addressing requirements of a device.
Memory Coalescing (most important)
global memory
Although the bandwidth of the global memory is big, the latency is as high as 400-800 cycles. Load and store multiple times can be very time consuming and inefficient.
L1 and L2 Cache
- L1 cache is 128-bytes aligned
- Multiples of 128B are read
- L2 cache is 32-bytes aligned
- Multiples of 32-bytes are read
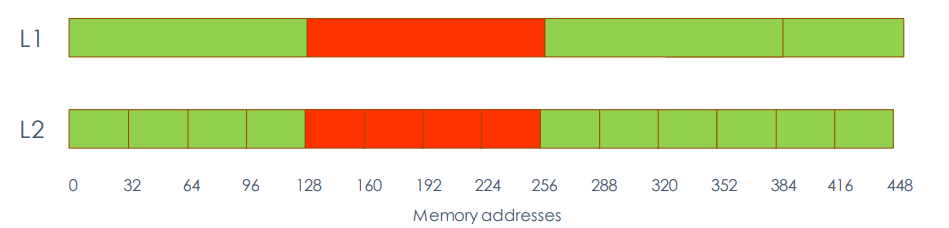
Memory Coalescing (caching or non-caching)
Global Memory -> caching
- For Fermi, Global Memory -> L1 cache allowed (default)
- It can be changed into Global Memory -> L2 cache
- by adding flags wen compiling, as
nvcc -Xptxas -dlem=cg
- For Kepler and newer, L1 is reserved for Local Memory
- Only Global Memory -> L2 caching
conditions
When a warp requests 32 aligned, 4-byte words, there are several conditions:
| warp word requested | threads word requested | caching | cache-lines | data move across the bus | Bus utilization |
|---|---|---|---|---|---|
| 32 aligned, 4-byte | 32 threads requesting 1 float each (continuous in memory) | L1 | 1 | 128 bytes | 100% |
| 32 aligned, 4-byte | 32 threads requesting 1 float each (not sequentially indexed) | L1 | 1 | 128 bytes | 100% |
| 32 aligned, 4-byte | 32 threads requesting 1 float each (not all continuous in memory) | L1 | 2 | 256 bytes | 50% |
| 32 aligned, 4-byte | 32 threads requesting 1 float each (not all continuous in memory) | L2 | 5 | 160 bytes | 80% |
| 1 4-byte | ALL 32 threads requesting 1 float value | L1 | 1 | 128 bytes | 3.125% |
| 1 4-byte | ALL 32 threads requesting 1 float value | L2 | 1 | 32 bytes | 12.5% |
| 32 scattered 4-byte | 32 threads requesting 1 float each (randomly) | L1 | N | N * 128 bytes | 128 / (N * 128) |
| 32 scattered 4-byte | 32 threads requesting 1 float each (randomly) | L2 | N | N * 32 bytes | 128 / (N * 32) |
.png)
.png)
.png)
%20on%20L2.png)
.png)
%20L2.png)
principle
requesting large, consecutive locations instead of random locations
Memory coalescing – rearrange access patterns to improve performance
- Useful today but will be less useful with large on-chip caches
The GPU coalesces consecutive reads in a full-warp into a single read
example
When accessing matrix data, avoid single thread requesting consecutive locations.
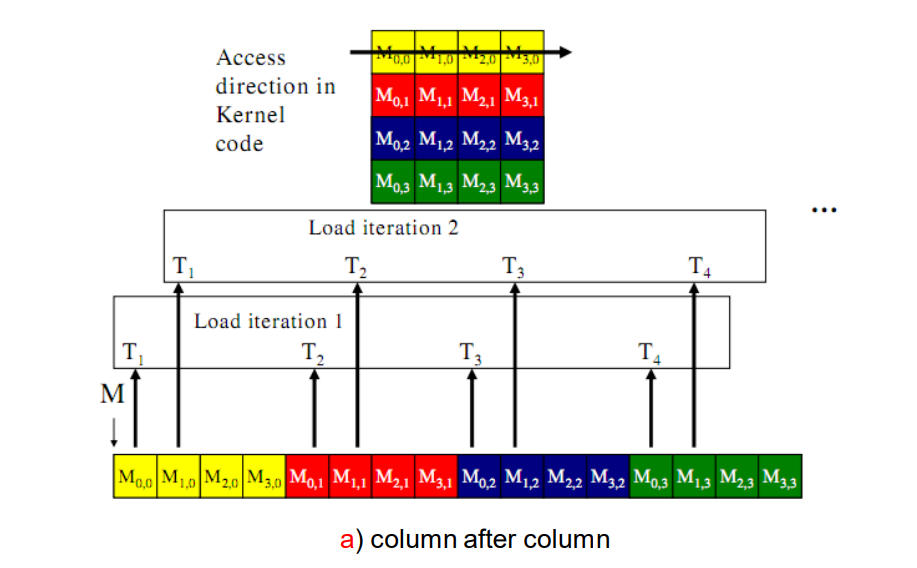
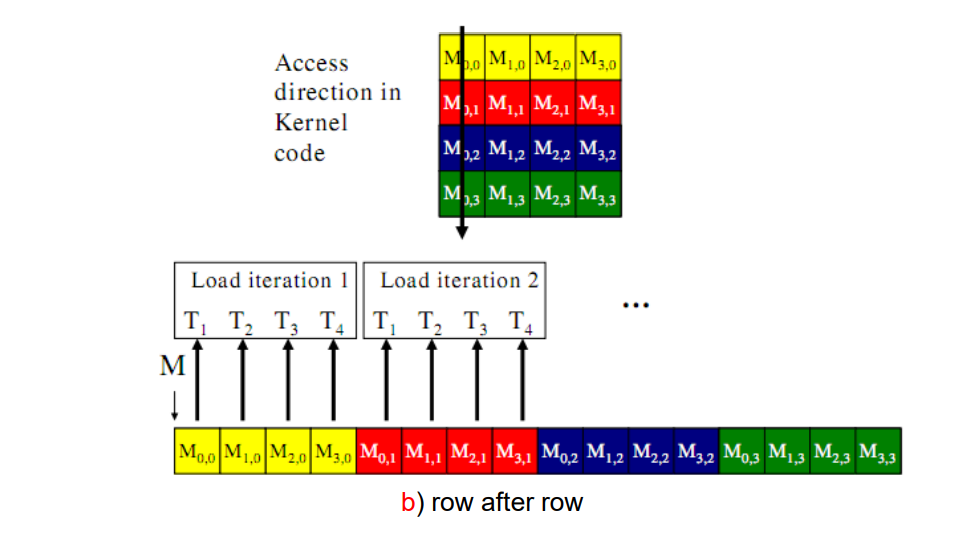
Share memory
What if it is impossible to request memory concecutively? It happens especially for the high dimensional conditions.
Strategy:
load global memory in a coalesce-able fashion into shared memory
Then access shared memory randomly at maximum bandwidth
Much lower latency then global memory.
Reduce the access of global memory
Inter-thread communication within a block
Bank Conflicts
When called a parallel data cache, multiple threads can access shared memory at the same time.
Share memory is divided into 32 32-bit banks banks
- Can be accessed simultaneously
- Requests to the same bank are serialized
Banks
- Each bank can service one address per two cycles
- Per-bank bandwidth: 32-bits per two cycles
- Successive 32-bit words are assigned to successive banks

example
__shared__ float tile[64];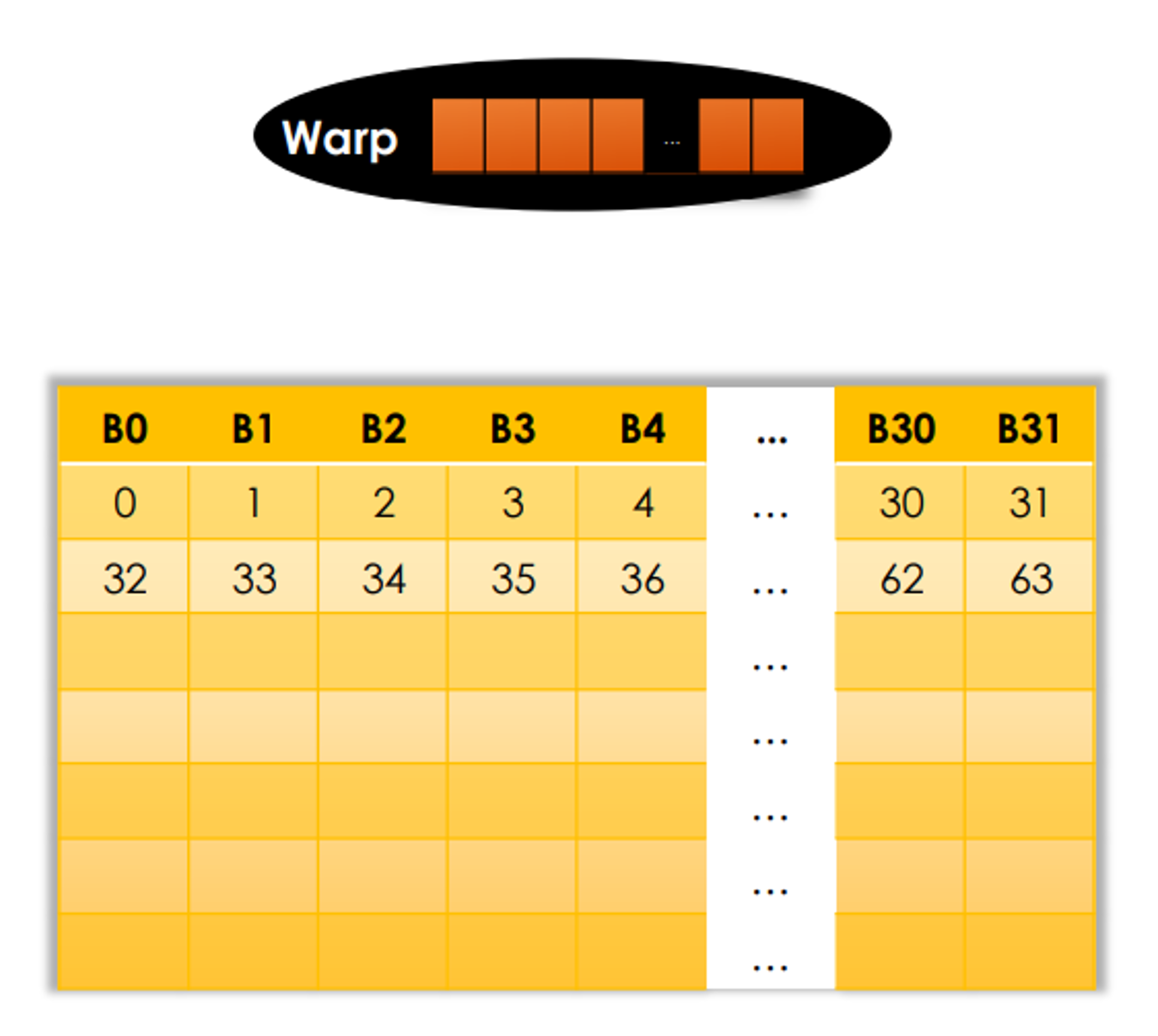
Bank Conflict
Two simultaneous accesses to the same bank, but not the same address,
- The memory accessing will be run serialized
- G80-GT200: 16 banks, with 8 SPs concurrently executing
- Fermi & Newer: 32 banks, with 16 SPs concurrently executing
conditions
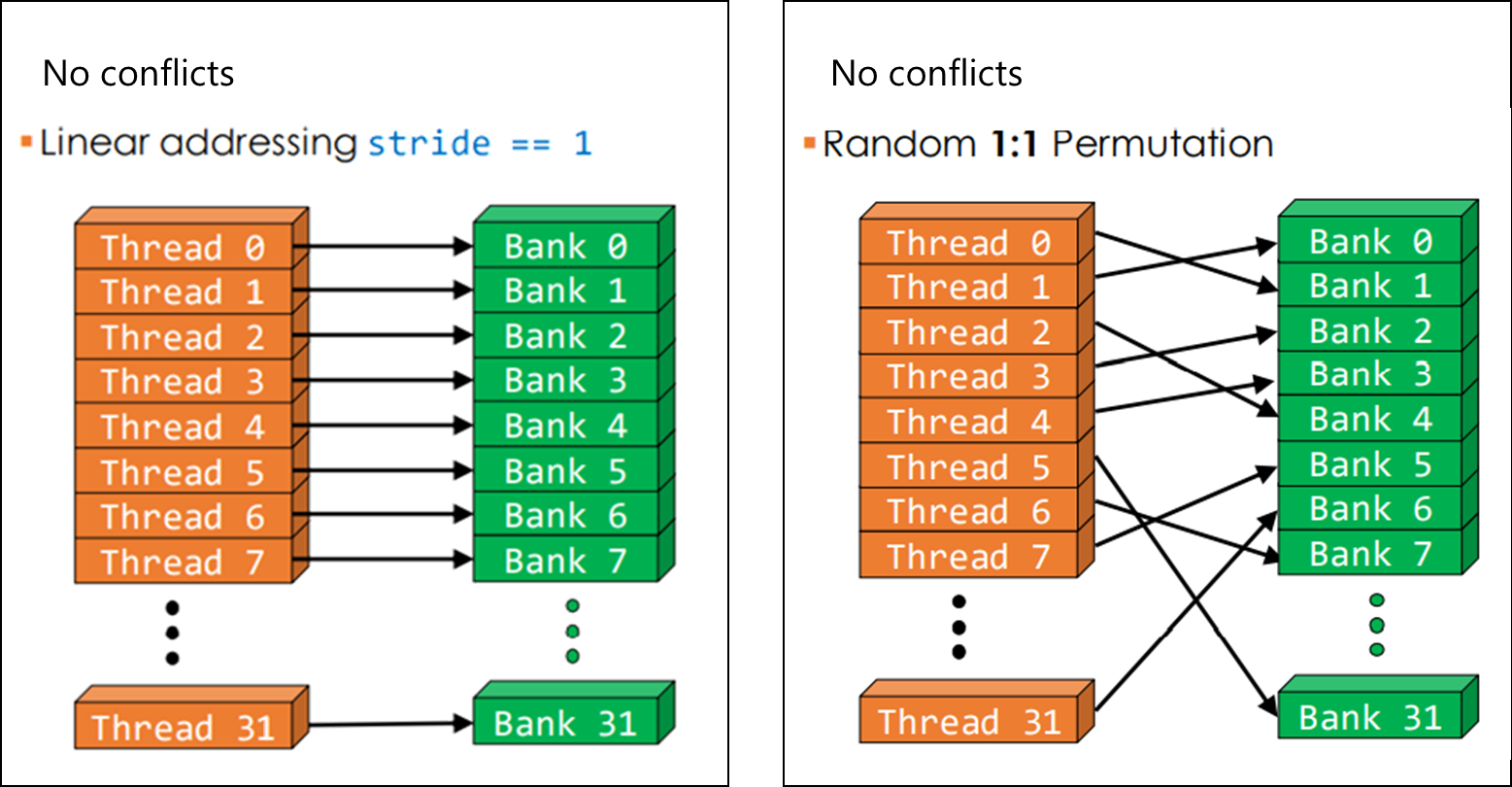
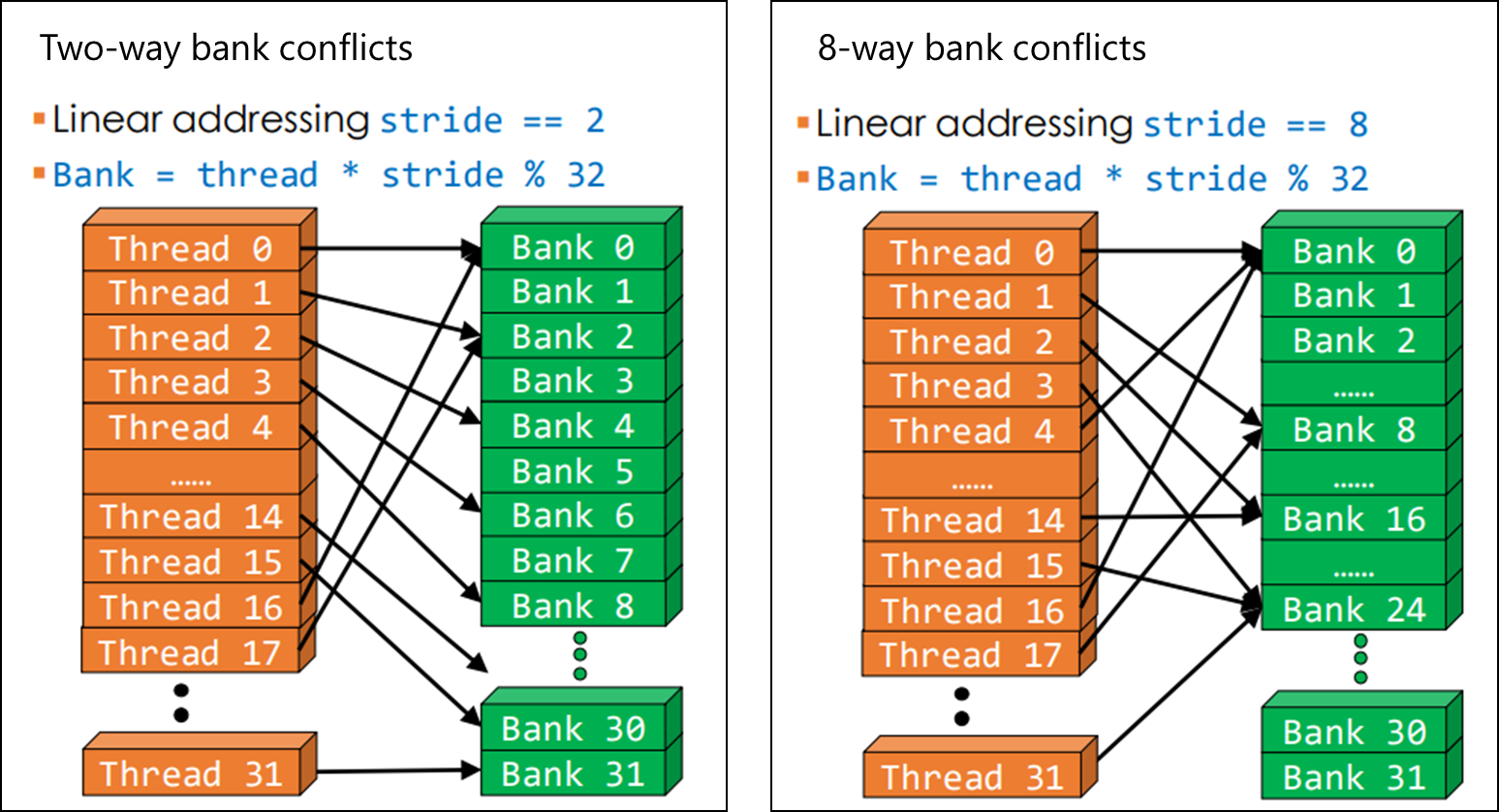
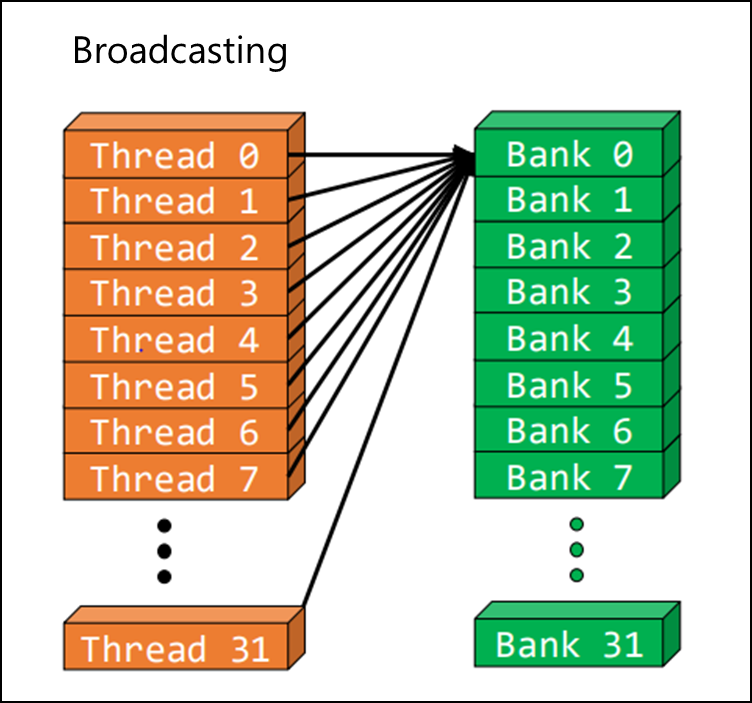
The latency of share memory is comparable with the registers, when no bank conflicts.
The conflicts can be detected by warp_serialize profiler.
examples
- Access to different banks by a warp executes in parallel.
__shared__ float tile[64];
int tidx = threadidx.x;
float foo = tile[tidx] - 3;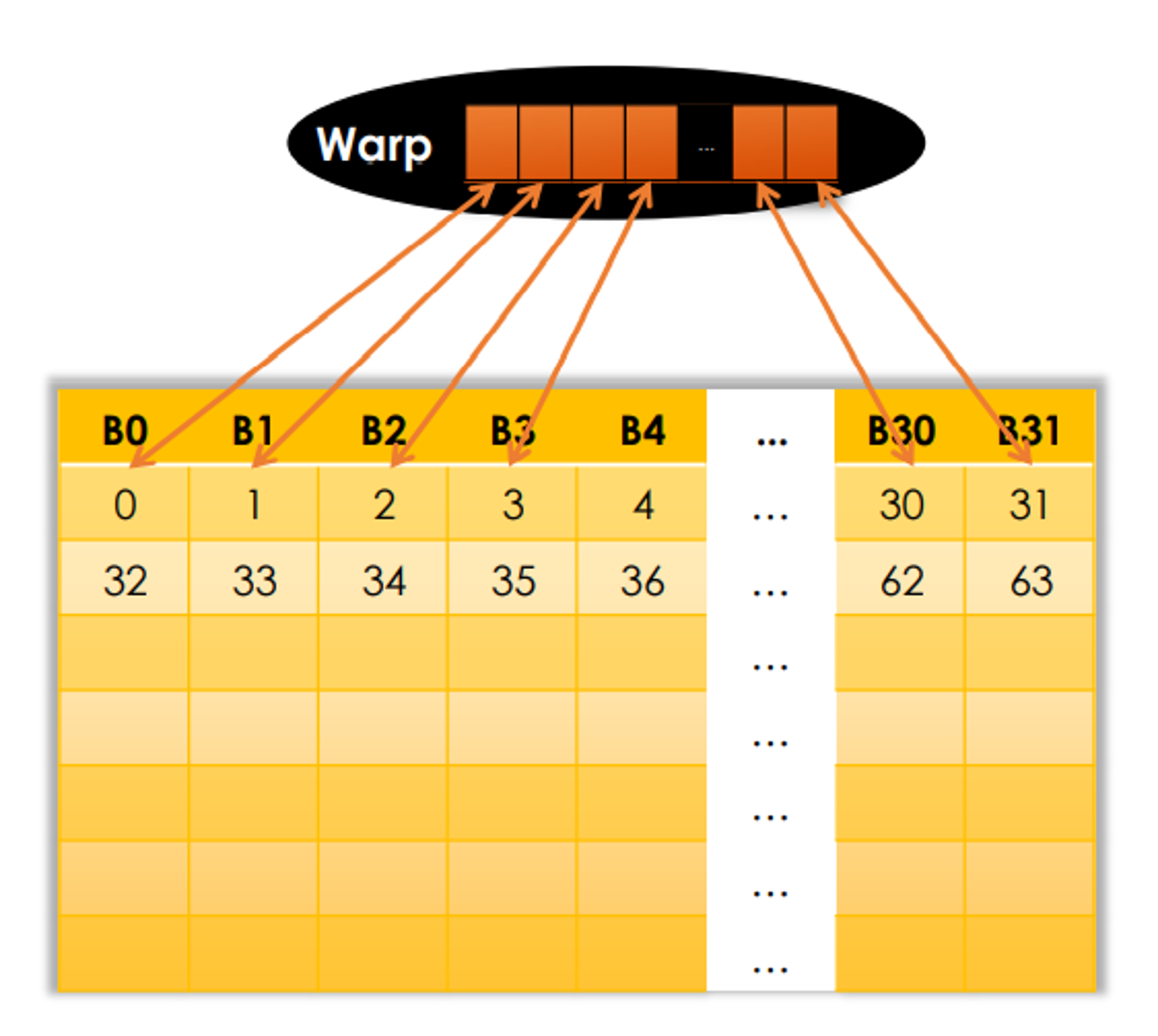
Access to same element of bank by a warp executes in parallel.
__shared__ float tile[64]; int tidx = threadidx.x; int bar = tile[tidx - tidx % 2];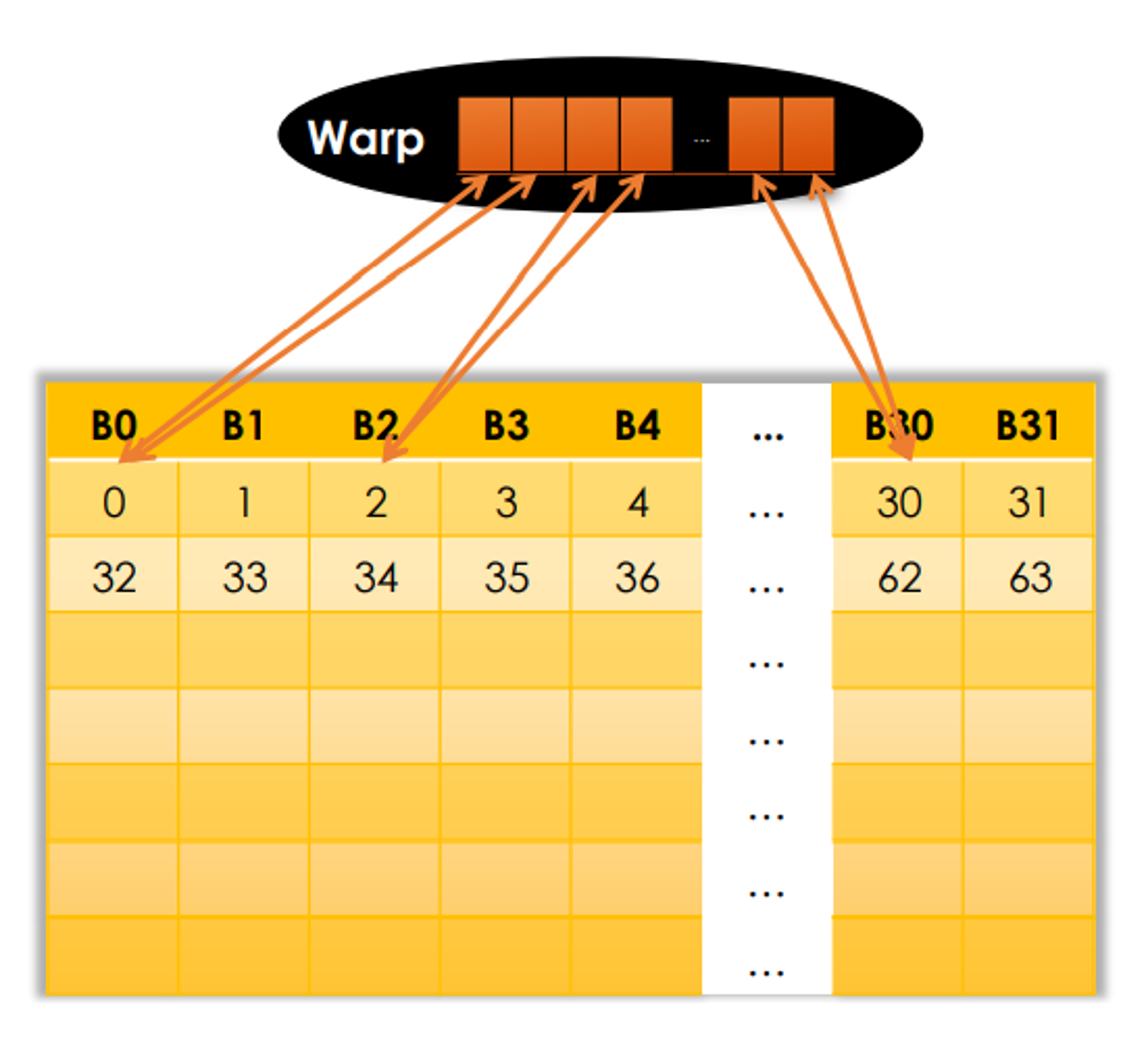
Access to defferent element of bank by a warp executes in serial
- 2-way conflict
__shared__ float tile[64]; int tidx = threadidx.x; int bar = tile[tidx + tidx % 2 * 31];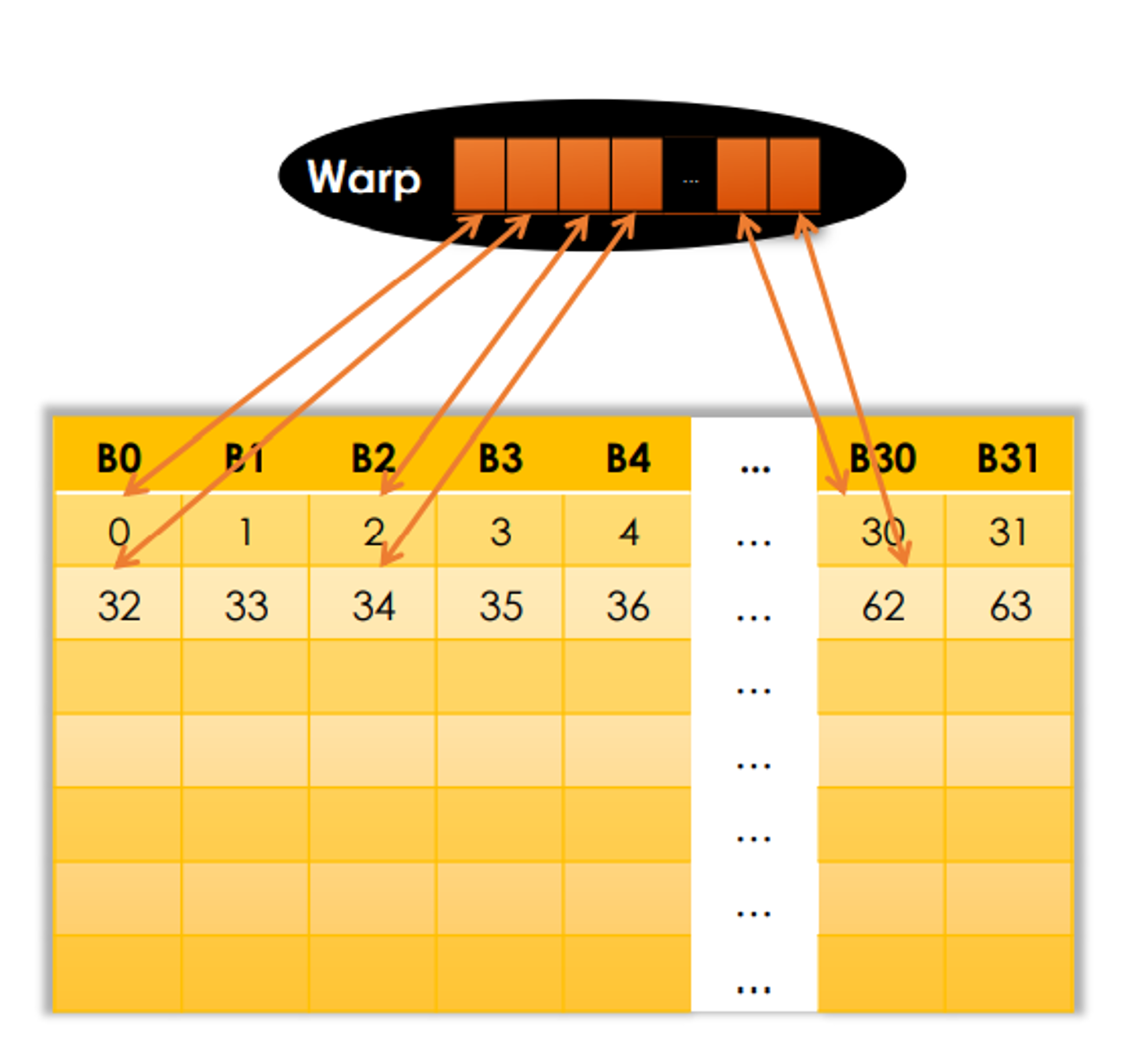
Fermi vs Kepler & Newer
Fermi (Compute 2.x)
- Bank width: 32-bits for 2 clock cycles
Kepler (Compute >= 3.x)and newer
- Bank width: 64-bits per 1 clock cycle
- Also 2 modes - either successive 32-bit words (in 32-bit mode) or successive 64-bit words (64-bit mode) are assigned to successive banks. So bank conflicts can still occur.
Note: (*) However, devices of compute capability 3.x typically have lower clock frequencies than devices of compute capability 2.x for improved power efficiency
Example Matrix Transpose
Inherently parallel - Each element independent of another
Simple to implement
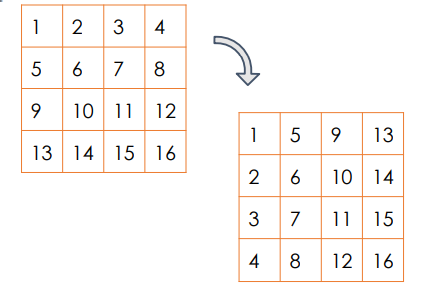
CPU
for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
transpose[i][j] = matrix[j][i]
}
}- O(n2 ) slow
GPU V1
__global__ void matrixTranspose(float *_A, float *_A_t)
{
int row = blockDim.y*blockIdx.y+threadIdx.y;
int col = blockDim.x*blockIdx.x+threadIdx.x;
_A_t[row*sizeX+col] = _A[col*sizeY+row];
}O(1) - Launch 1 thread per element
Essentially one
memcpyfrom global-to-global
should be fast YET:
Problem
Memory coalescing, recall the matrix accessing example,
- when row-major: consecutive locations when loading yet scattered locations on writing
- when col-major: consecutive locations when writing yet scattered locations on loading
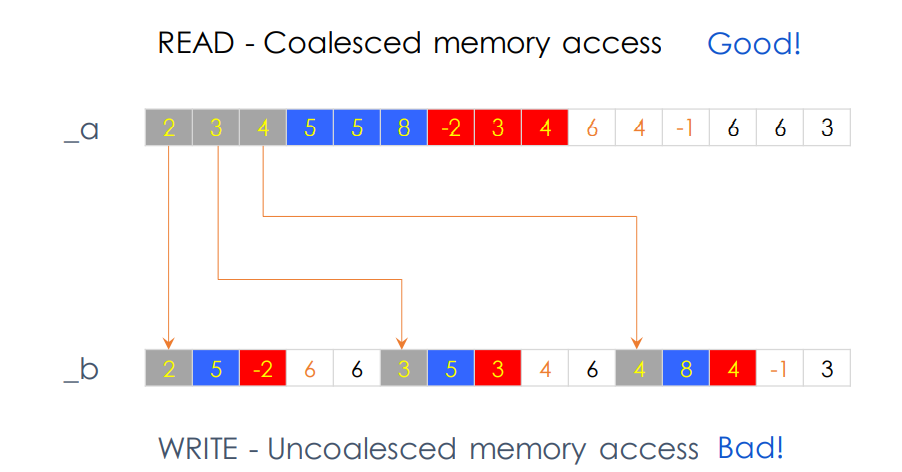
Improvement
Recall the share memory, we can make both the global memory <--> share memory coalesced in both directions.
GPU V2
Compute input index (same as in naive transpose)
Copy data to shared memory
Compute output index
Remember, coalesced memory access
Hint, transpose only in shared memory
Copy data from shared memory to output
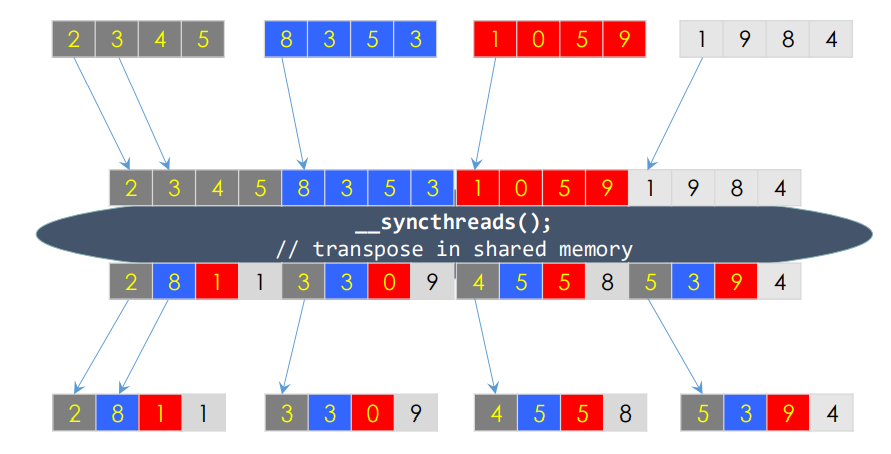
__global__ void matrixTransposeShared(const float *_a, float *_b)
{
__shared__ float mat[BLOCK_SIZE_Y][BLOCK_SIZE_X];
int bx = blockIdx.x * BLOCK_SIZE_X;
int by = blockIdx.y * BLOCK_SIZE_Y;
int i = bx + threadIdx.x; //input
int j = by + threadIdx.y; //input
int ti = by + threadIdx.x; //output
int tj = bx + threadIdx.y; //output
if(i < sizeX && j < sizeY)
{
mat[threadIdx.y][threadIdx.x] = a[j * sizeX + i]; // read
}
__syncthreads(); //Wait for all data to be copied
if(tj < sizeY && ti < sizeX)
{
b[tj * sizeY + ti] = mat[threadIdx.x][threadIdx.y]; // write
}
}Problem
Recall bank conflict,
Access to defferent element of bank by a warp executes in serial, as a result ,when writing, there is a
- 32-way conflict
b[tj * sizeY + ti] = mat[threadIdx.x][threadIdx.y];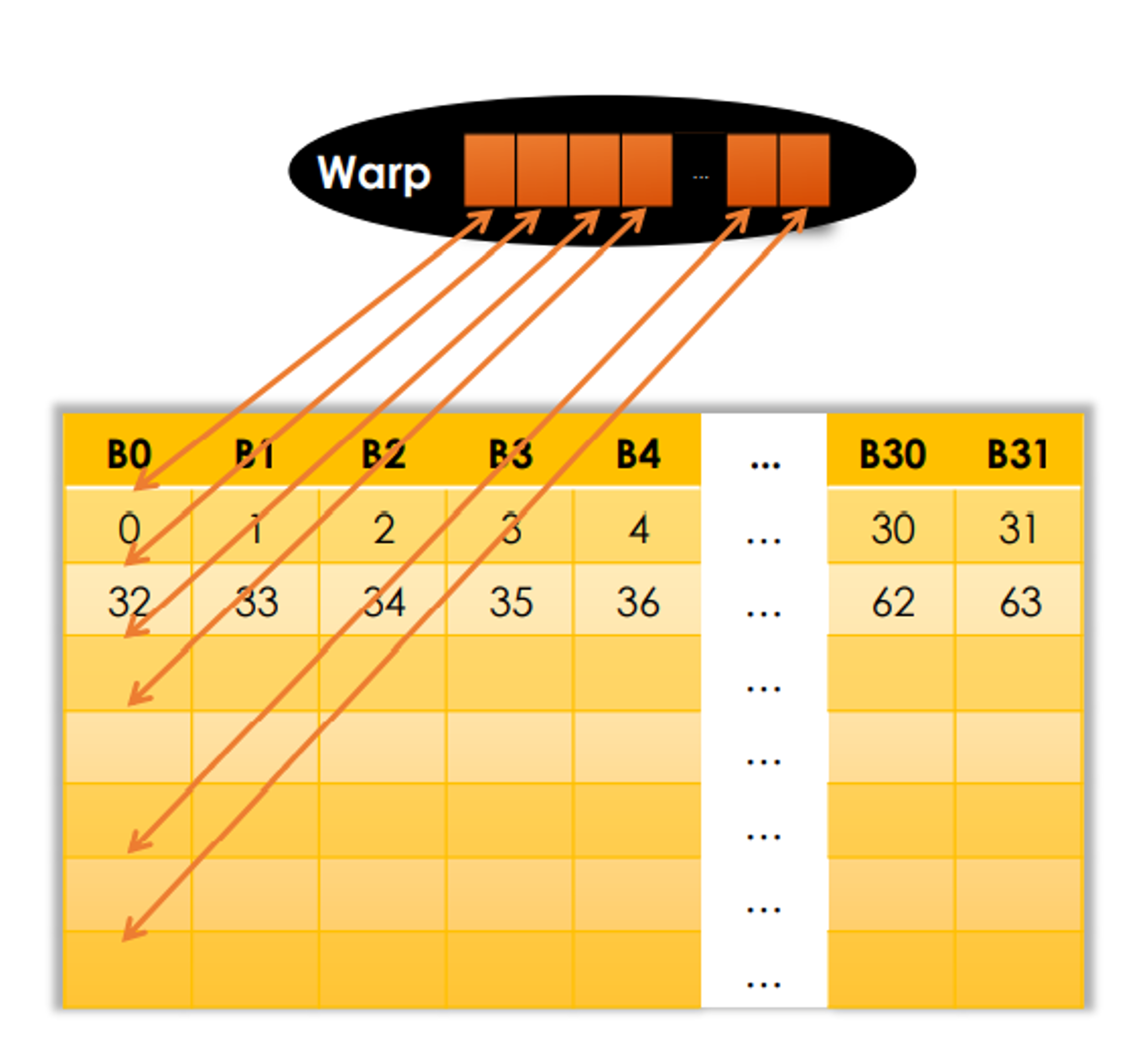
Improvement
Resolving bank conflict by stuffing blank element at the end of each bank.
GPU V3
// __shared__ float mat[BLOCK_SIZE_Y][BLOCK_SIZE_X];
__shared__ float mat[BLOCK_SIZE_Y][BLOCK_SIZE_X + 1];
// ...
b[tj * sizeY + ti] = mat[threadIdx.x][threadIdx.y]Elements per row = 32
Shared Mem per row = 33
1 empty element per row
Now it is very very close to production ready!
Furthere improvements
More work per thread - Do more than one element
Loop unrolling
GPU V4
More work per thread:
- Threads should be kept light
- But they should also be saturated
- Give them more operations
Loop unrolling
Allocate operation in a way that loops can be unrolled by the compiler for faster execution
Warp scheduling
Kernels can execute 2 instructions simultaneously as long as they are independent
Use same number of blocks, shared memory
- Reduce threads per block by factor (
SIDE)
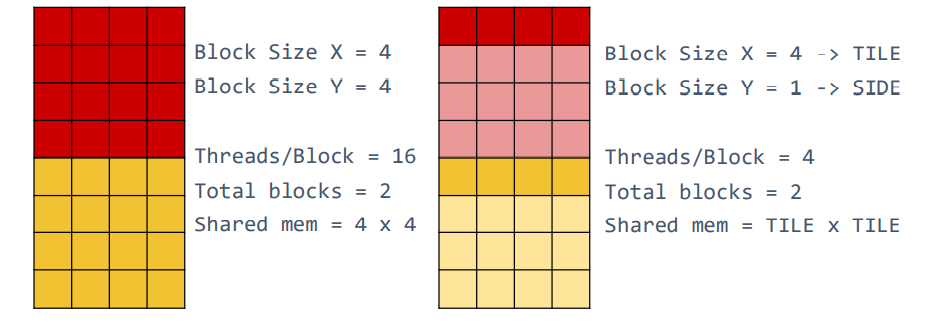
- Reduce threads per block by factor (
| HOST | DEVICE |
|---|---|
| Same number of blocks | Allocate same shared memory |
| Compute new threads per block | Compute input indices similar to before |
| Copy data to shared mem using loop (k) - Unrolled index: add k to y |
|
| Compute output indices similar to before | |
| Copy data from shared memory into global memory - Unrolled index: add k to y |
template<int TILE, int SIDE> //TILE = 32, SIDE = 8
__global__ void matrixTransposeUnrolled(const float* a, float* b)
{
//Allocate appropriate shared memory (avoid bank conflict)
__shared__ float mat[TILE][TILE + 1];
//Compute input index
int x = blockIdx.x * TILE + threadIdx.x;
int y = blockIdx.y * TILE + threadIdx.y;
//Copy data from input to shared memory. Multiple copies per thread.
#pragma unroll
for (int k = 0; k < TILE; k += SIDE)
{
if (x < sizeX && y + k < sizeY)
{
mat[threadIdx.y + k][threadIdx.x] = a[((y + k) * sizeX) + x];
}
}
__syncthreads();
//Compute output index
x = blockIdx.y * TILE + threadIdx.x;
y = blockIdx.x * TILE + threadIdx.y;
//Copy data from shared memory to global memory. Multiple copies per thread.
#pragma unroll
for (int k = 0; k < TILE; k += SIDE)
{
if (x < sizeY && y + k < sizeX)
{
b[(y + k) * sizeY + x] = mat[threadIdx.x][threadIdx.y + k];
}
}
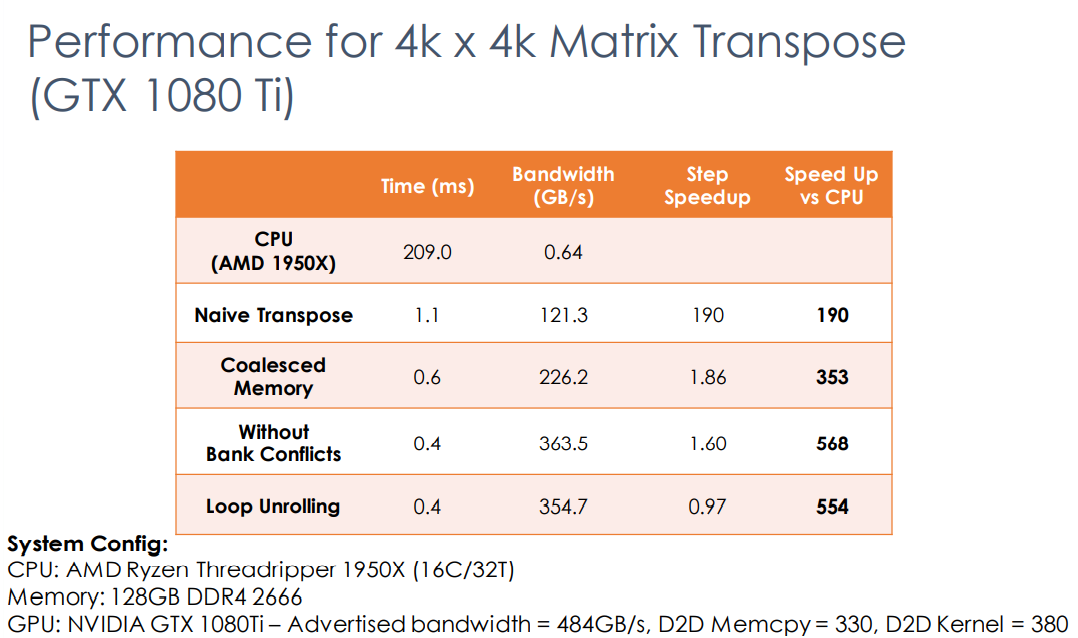
}Benchmark result
Divergent Optimisation
Example Parallel Reduction
Example first this time
Reduction: An operation that computes a single result from a set of data. For example the sum and max
sum
With data $[a] = $: \[ \left[0\right] \qquad \left[1\right] \qquad \left[2\right] \qquad \left[3\right] \qquad \left[4\right] \qquad \left[5\right] \qquad \left[6\right] \qquad \left[7\right] \qquad \]
Need to calculate the in parallel \[ s = \sum_ {i=0}^N a_i \]
Serial vs Parallel
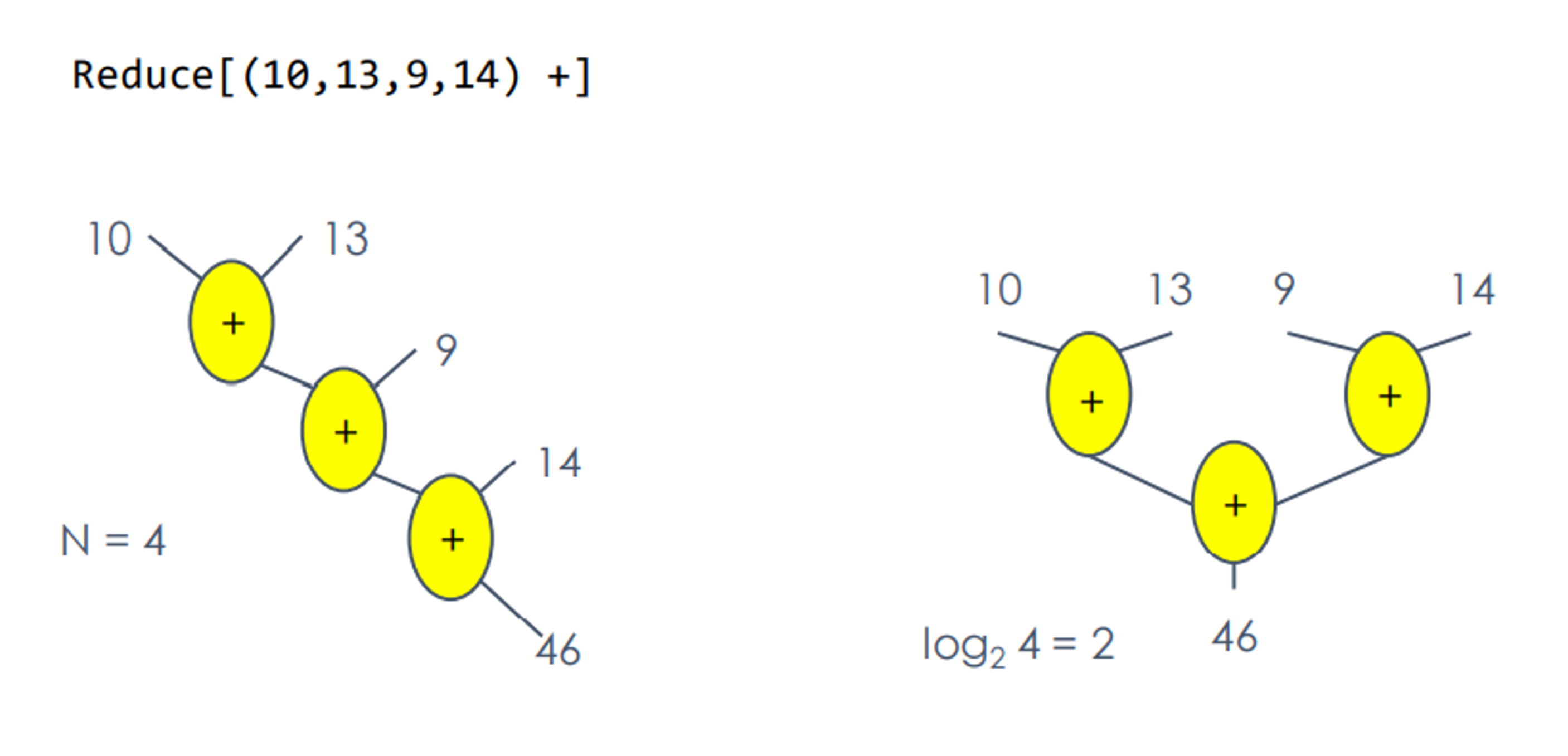
It is obvious, the merits of parallel reduce are:
- Binary
- example:
a * b,a + b,a & b,a | b - not binary:
!(a),(a)!
- example:
- Associative
- example:
a * b,a + b,a & b,a | b - non associative:
a / b,a - b
- example:
GPU V1: Interleaved Addressing
Parallel binary reduce is applied to a part of the whole array in each block.
Multiple blocks help in:
- Maximizing Occupancy by keeping SMs busy
- Processing very large arrays.
Parallel reduce is not arithmetic intensive, it takes only 1 Flop per thread(1 add) so it is completely memory bandwidth bounded.
Need a way to communicate partial results between blocks
- Global sync is not practical due to the overhead of sync across so many cores
- Solution: Call the reduce kernel recursively to reduce the results from previous reduce
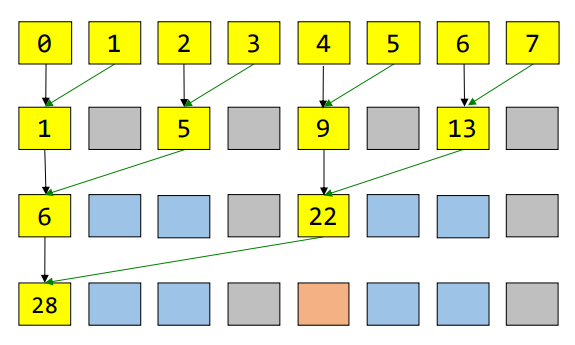
\(\log_2(n)\) passes for n elements
\(O(\log_2n)\) complexity
code
- Declare dynamic shared memory and compute index
- Load input into shared memory
- Reduce in shared memory
- Copy result of each block into global memory
We only modify Parts 2 and 3 for optimization
__global__ void reduce_v1(const float* d_idata, float* d_odata, int n)
{
// step 1
// Dynamic allocation of shared memory - See kernel call in host code
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x; // Calculate 1D Index
// step 2
if(idx < n)
{
smem[threadIdx.x] = d_idata[idx]; // Copy input data to shared memory
}
__syncthreads();
// step 3
// Reduce within block
// Start from c = 1, up to block size, each time doubling the offset
for(int c = 1; c < blockDim.x; c *= 2)
{
if (threadIdx.x % (2 * c) == 0)// Add only on left index of each level
{
smem[threadIdx.x] += smem[threadIdx.x + c];
}
__syncthreads();
}
// step 4
// Copy result of reduction to global memory
if(threadIdx.x == 0)
{
d_odata[blockIdx.x] = smem[0];
}
}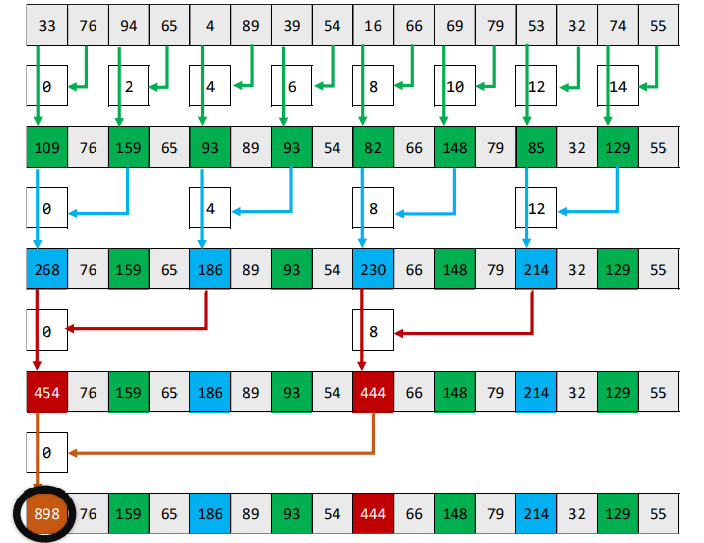
1st pass: threadid.x = 0, 2, 4, 6 ... are working while the others keep idle.
2st pass: threadid.x = 0, 4 ... are working while the others keep idle.
3st pass: threadid.x = 0 ... are working while the others keep idal.
At each pass, number of threads required is halved. The idle threads doubled.
note that the as stride increases, the not-working threads do the same work with the working threads. Because threads in the same warp need to run exact the same computations. Yet no registered are allocated to them.
problems:
Interleaved addressing
Too many divergent branches
Improvement
Avoiding using modulo operator
%Non-divergent branches
Warp revision
A thread block is broken down to 32-thread warps, warps are executed physically in a SM(X)
Total number of warps in a block: ceil(T/Wsize)
Each thread in a warp execute one common instruction at a time
Warps with diverging threads execute each branch serially
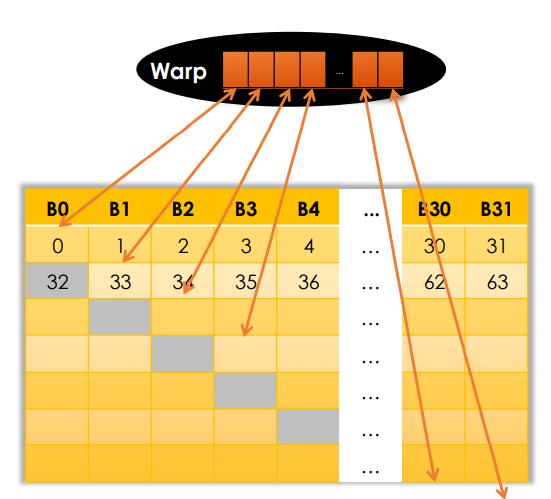
Warp Partitioning
Definitions
Warp Partitioning: how threads from a block are divided into warps - based on consecutive increasing threadIdx.
Knowledge of warp partitioning can be used to:
- Minimize divergent branches
- Retire warps early
Recall the divergent branches inside one warp: the performance can be largely deterited.
examples
For warpSize = 32,
the code below will cause divergence inside a warp.
if (threadIdx.x > 15) { // ... }the code below suffers no from the branch divergence
if (threadIdx.x > warpSize - 1) { // ... }because the divergence happens across the warps.
Rule
Make threads per blocks to be a multiple of a warp (32)
- Incomplete warps waste unused cores
- 256 threads per blocks is a good starting point
Try to have all threads in warp execute in lock step
- Divergent warps will use time to compute all paths as if they were in serial order
GPU V2: Removing divergence branching
Revise the problems existing
Interleaved addressing
Too many divergent branches
Now we are dealing with the second one.
__global__ void reduce_v2(const float* d_idata, float* d_odata, int n)
{
// step 1 and 2 ...
// step 3
for(int c = 1; c < blockDim.x; c *= 2)
{
int index = threadIdx.x * 2 * c;
if (index < blockDim.x) // No divergence except last warp
{
smem[index] += smem[index + c];
}
__syncthreads();
}
// step 4 ...
}Simple modification but
Need to change the for-loop structure
Need the same values, just not the modulo etc
Restructure
GPU V3: Sequential Addressing
Now we are dealing with the first problem.
__global__ void reduce_v2(const float* d_idata, float* d_odata, int n)
{
// step 1 and 2 ...
// step 3
// Reduce within block
for(int c = blockDim.x / 2; c > 0; c >>= 1)
{
// No need for index or modulo. It is replaced by c – similar to stage 0
if (threadIdx.x < c)
{
smem[threadIdx.x] += smem[threadIdx.x + c];
}
__syncthreads();
}
// step 4 ...
}note that bitwise shifting
>>substitutes the/operation.
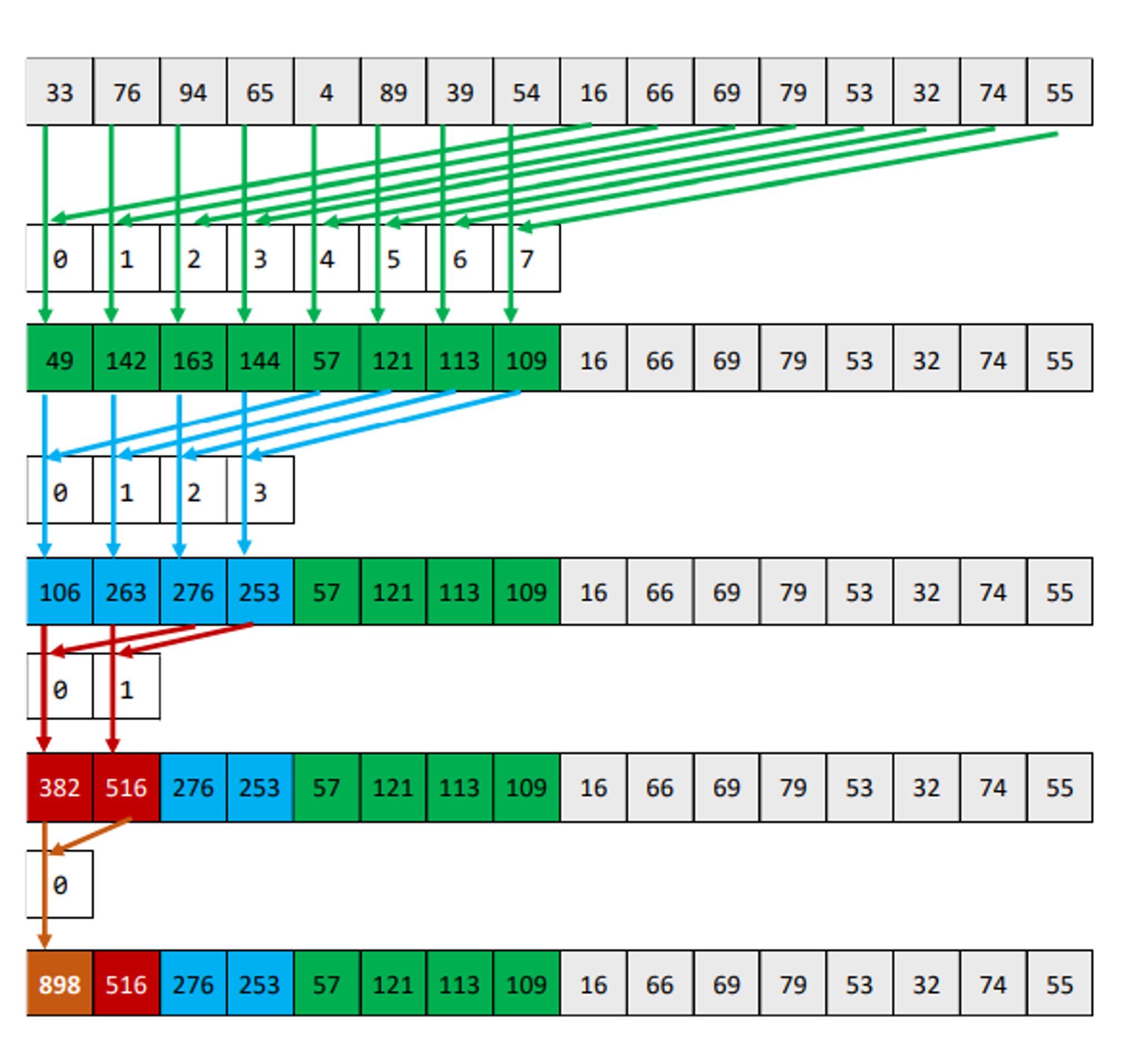
1st pass: threadid.x = 0, 1, 2, 3 ... are working while ( 1/2) keep idle.
2st pass: threadid.x = 0, 1 ... are working while ( 3/4) keep idle.
3st pass: threadid.x = 0 ... are working while ( 7/8) keep idal.
...
At each pass, number of threads required is halved.
The idle threads are able to release because the indexes of the working threads are changed.
Compared with V1/2:
Suppose the warpSize = 2
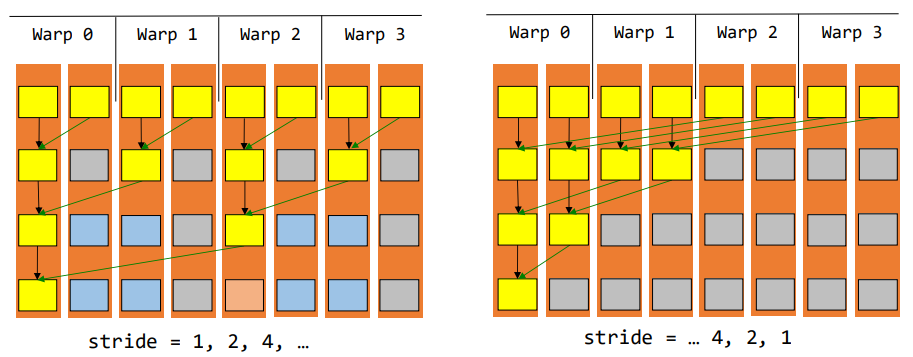
Given the knowledge of warp partitioning
| Pass number | Original | Optimised |
|---|---|---|
1st pass |
4 divergences, 0 warp can be retired | 0 divergence, 2 warps can be retired |
2st pass |
2 divergences, 2 warp can be retired | 0 divergences, 3 warps can be retired |
3st pass |
1 divergence, 3 warps can be retired | 1 divergence, 3 warps can be retired |
Problem
Always think of:
- Last warp divergence?
- Memory Coalescing?
- Bank conflicts?
- How is thread usage?
Imporvements
How to reduce the idel warps?
- Launch only half the threads per block
- reduce the threads load in step 2
- Get’s rid of maximum wastage
- How to load data into shared memory?
- adding on Load
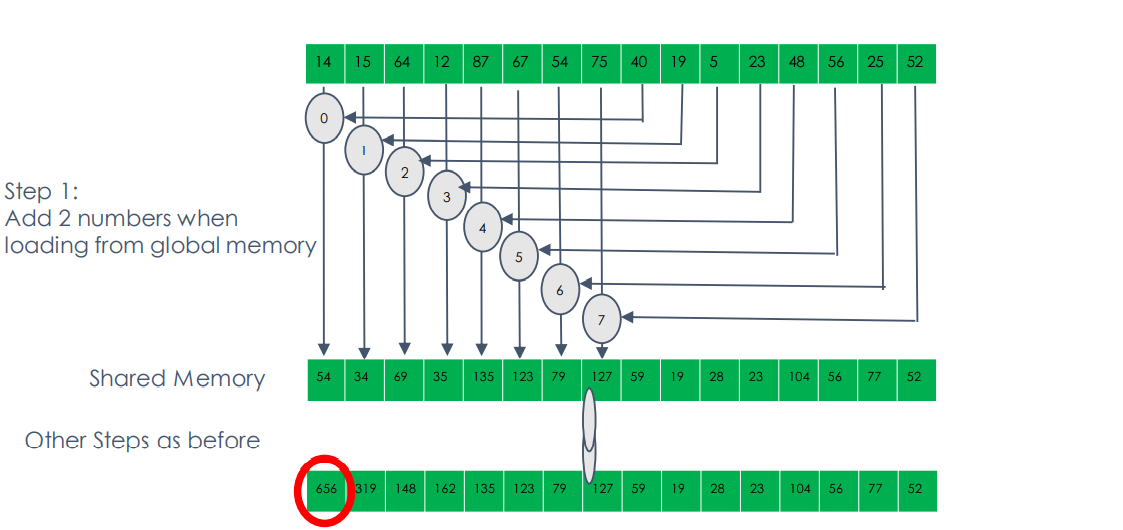
GPU V4.1: Single add on load
Each thread reads multiple values into shared memory. So why not add on load too?
- Doesn’t increase our global memory usage
- Also reduces the amount of shared memory we need
- Or keep shared memory same and do more work per block
__global__ void reduce_v1(const float* d_idata, float* d_odata, int n)
{
// step 1
// step 2
if(idx < n)
{
smem[threadIdx.x] = d_idata[idx];
//Copy and add block data into shared memory
if(idx + blockDim.x < n)
{
smem[threadIdx.x] += d_idata[idx + blockDim.x];
}
}
__syncthreads();
// step 3
// step 4
}
Problem
Single - the threads needed is halved only in the first pass
Improvement
Multiple adds per thread on load
- Replace single add with a loop.
- Use a counter TILE to define the number to adds per thread
- defining TILE as global constant will allow loop unrolling
- preferable set TILE as power of 2
GPU V4.2: Multiple adds on load
__global__ void reduce_v1(const float* d_idata, float* d_odata, int n)
{
// step 1
// step 2
if(idx < n)
{
smem[threadIdx.x] = 0; // Start with identity
for(int c = 0; c < TILE; c++)
{
// Copy and add block data with block offset into shared memory
if(idx + c * blockDim.x < n)
{
smem[threadIdx.x] += d_idata[idx + c * blockDim.x];
}
}
}
__syncthreads();
// step 3
// step 4
}problem
Last warp is still divergent
solution
Unroll the last warp
GPU V5.1: Last warp unroll
Split the step 3 into 2 steps:
__global__ void reduce_v2(const float* d_idata, float* d_odata, int n)
{
// step 1 and 2 ...
// step 3
// step 3A
for(int c = blockDim.x / 2; c > 32; c >>= 1)
{
// No need for index or modulo. It is replaced by c – similar to stage 0
if (threadIdx.x < c)
{
smem[threadIdx.x] += smem[threadIdx.x + c];
}
__syncthreads();
}
// step 3B
if(threadIdx.x < 32)
{
warpReduce(smem, threadIdx.x);
}
// step 4 ...
}with
__device__ void warpReduce(volatile float* smem, int tid)
{
//Write code for warp reduce here
smem[tid] += smem[tid + 32];
smem[tid] += smem[tid + 16];
smem[tid] += smem[tid + 8 ];
smem[tid] += smem[tid + 4 ];
smem[tid] += smem[tid + 2 ];
smem[tid] += smem[tid + 1 ];
}note that volatile is used to declare smem
The compiler doesn't reorder stores to it and induce incorrect behavior.
Basically – Tell compiler we know what we are doing
There is no need for if(threadIdx.x < c), Essentially, when we write to the Nth part of the warp/block shared memory, we don’t really care about that data anymore.
The cost is nothing – We are executing threads that were sitting idle before.
Improvement
Able to unroll compeletely?
GPU V5.2: Complete unroll
Taking inspiration from Stage 4, unroll the for loop entirely in step 3A
#pragma unroll requires sizes to be known at compile time
Use Templates
CUDA supports C++ template parameters on device and host functions
Specify block size as a function template parameter:
reduce_v5<threads><<<dims.dimBlocks, dims.dimThreads, sizeof(float) * dims.dimThreads >>> (d_idata, d_odata, n_elements);
Block size in GPU limited to 512 or 1024 threads.
- Only a limited number of
ifconditions we have to write
Also make block sizes power of 2 (preferably multiples of 32).
if(blockSize >= 1024)
{
if(threadIdx.x < 512) { smem[tid] += smem[tid + 512]; } __syncthreads();
}
if(blockSize >= 512)
{
if(threadIdx.x < 256) { smem[tid] += smem[tid + 256]; } __syncthreads();
}
if(blockSize >= 256)
{
if(threadIdx.x < 128) { smem[tid] += smem[tid + 128]; } __syncthreads();
}
if(blockSize >= 128)
{
if(threadIdx.x < 64) { smem[tid] += smem[tid + 64]; } __syncthreads();
}Note that the blockSize is known at compile time
- All the if conditions related to
blockSizeare evaluated at compile time. - No problem with other if conditions either
- All guarantee no warp divergence
Benchmark
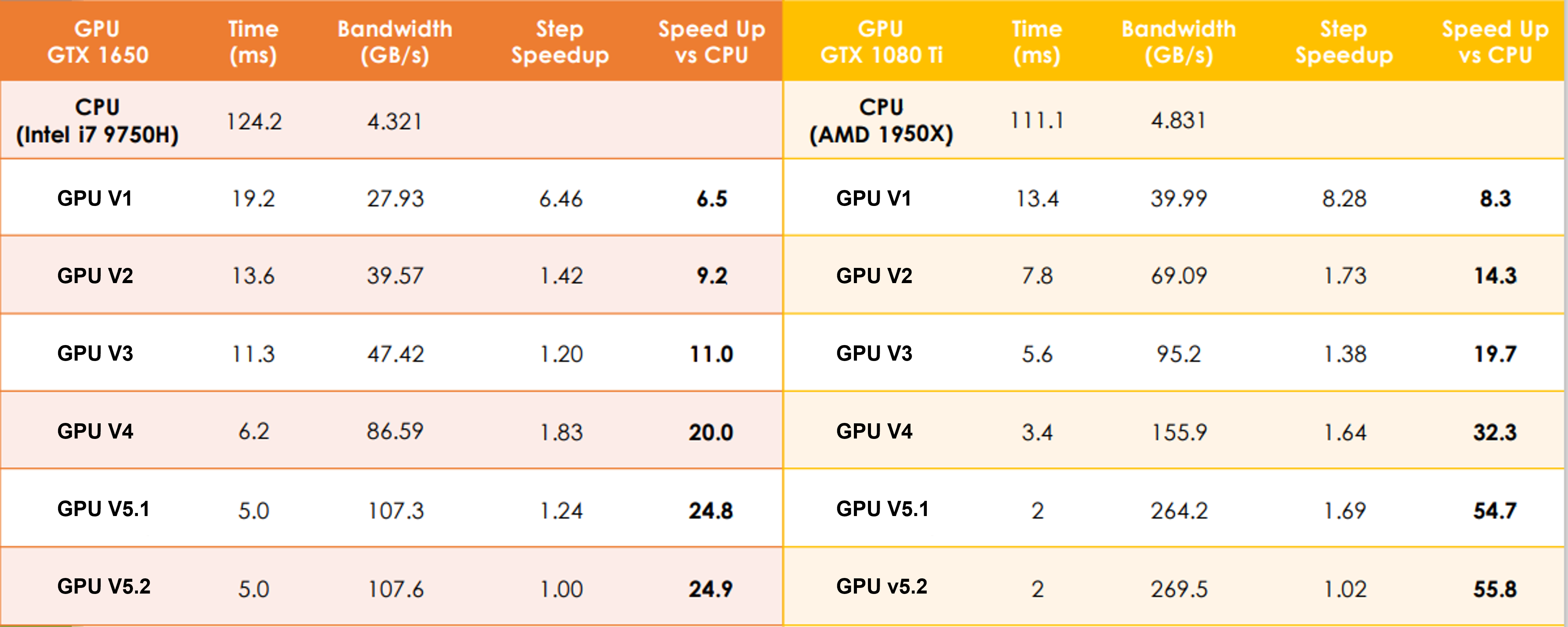
Further improvements
- RECURSIVE REDUCTION - Call recursion on result of block reduction – instead of CPU
- CONSTANT POINTER - use
const float* x;,float* const x;,const float* const x; __restrict__FLAG- assure the compiler that the pointer marked by it do not overlap
- Basically, a and b are exclusive memory
- And that you will not do indexing that will overflow into the other
- Compiler can make optimizations based on this
- Removes checks
Bank conflict
Conclusion
- Understand CUDA performance characteristics
- Memory coalescing
- Divergent branching
- Bank conflicts
- Latency hiding
- Use peak performance metrics to guide optimization
- Know peak GFLOPs and Memory Bandwidth of GPU
- Know how to identify type of bottleneck
- e.g. memory, core computation, or instruction overhead
- Optimise your algorithm, then unroll loops
- Use template gracefully
Final guide
- parallelisation
- memory coalsecing
- share memory
- other memory
- texture
- constant
- reduce bank conflicts