Build and train an opensource chatGPT locally
This is a conclusion of the last 5 blog, showing the key process of building and optimizing a chat bot backended by open source large language model.
2 months later, Meta published their own large language model LLaMA[1], ranging from 7B to 65B parameters. In the paper[2], they claimed that LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. While Meta claims that LLaMA is open source, it still requires researchers to apply and be reviewed. However, what I never expected was that the model file of LLaMA was LEAKED. Members of 4chan released a copy of the weight file for everyone to download within just a few days of its release.
Although there are apps like discord bot[3] out there, still, it's a good opportunity to build a own chatGPT from the scratch.
Interface
Vue.js and flask is used for front-end (modified from run27017/vue-chat) and backend, and axios is used for HTTP requests. This is the interface at this stage. See build a chatbot backended by Meta LLaMA language model for the source code and more details.
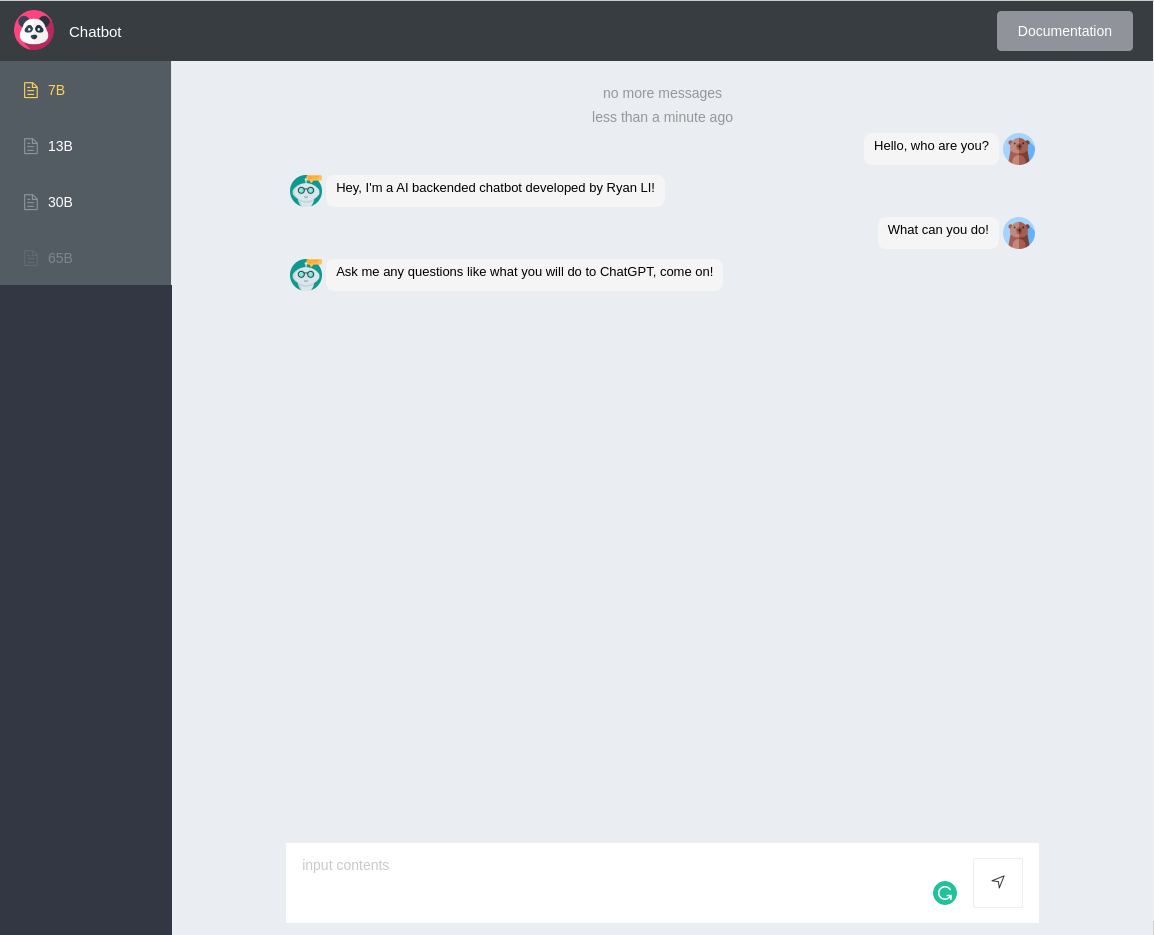
Current functions:
- select different models
- multiple lines input and output
- save chat histories for each ip address
TO DO
- remove the session limitation for each ip address
- render message box in markdown format
- add configuration panel allowing users to change model parameters
Language model
For the backend large language model, we've tained and tried 3 stages and 5 versions of optimizations.
- Open-source basic model
- original llama model
- optimized llama model, improved for chatting, using prompt engineering
- Stanford alpaca, follow their work to build a second developing process
- Personal trained alpaca using collected data
The sections below will follow this outline and illustrate the step-by-step optimization results.
basic llama
original llama
The original llama model (facebookresearch/llama) only performs next-word prediction, meaning
- it only generates the natural continue of the prompt
- it does not know where to stop
- it is not designed to answer questions.
- it does not support in-context chatting (no chat histories).
Here are 3 typical answers of the original 7B version:
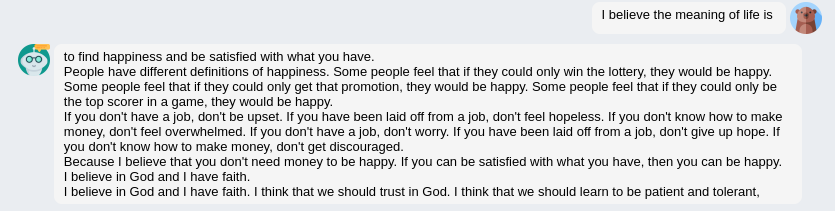

In Fig 2, we can see the reasonable result (first line) is always followed by a nonsense babbling that goes further and further away from the topic.
In next two conversations, we use few short learning [1][2] to give it a longer prompt with examples.
In Fig 3, after the correct answer (first line), it tends to prolong the given pattern (second line), then keeps babbling.
In Fig 4, where we provide a relatively longer example, it continues the pattern until the answer reach the
max_gen_len.
optimized llama
To address the problems, we designed a prompting strategy and a corresponding truncation method.
The typical results of the optimized 7B llama model are shown below:
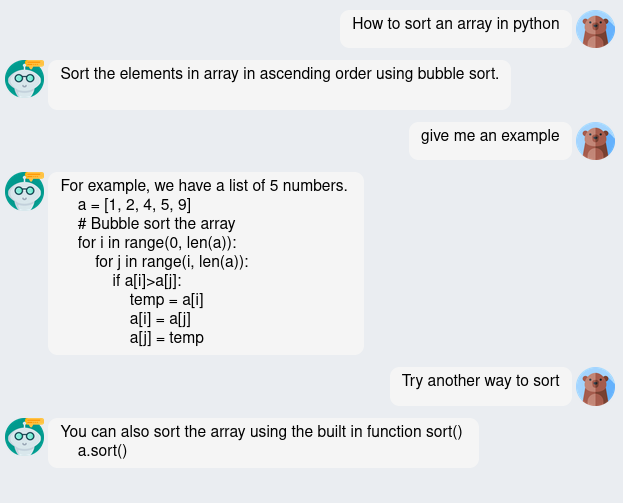

From the example, we can see it performs more like a consultant chatbot by:
- it stops generating garbage messages
- it knows where to stop
- it acknowledges of chat history
For the quality of its answers:
- In Fig 5, both the bubble sorting script and the python build-in sorting methods work.
- In Fig 6, for another longer conversation, it tries to give me some interesting information, but still not smart.
Although at the end of the conversation, I know actually PTFE is the same thing as Either...
Stanford alpaca
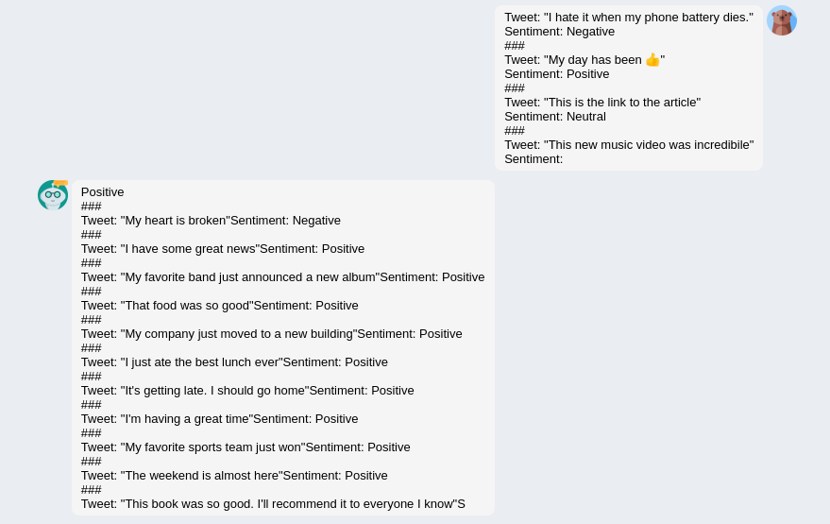
In order to further improve this model, Stanford Alpaca Project[3] provided one way taking self-instruct learning strategy. They also shared a 52K dataset for training, make their work easy to reproduce. Here is one of the results of the reporduced 7B stanford alpaca:

Note that we did not implement any postprocessing methods to its answer, by which the model gains up to 10 times less response time and bigger training potential.
In terms of the result, it looks good for the first 2 rounds. The model knows that this function means the built-in sort function in Python from the context. But in the 3rd round, the model starts to generate repetitive words.
This is because this model is not trained with conversation before. More specific datasets are needed to improve the conversation ability.
The most improtant thing is, from this framework, we are able to train any model with any dataset.
This means we can improve any abilities of the model by feeding it the corresponding training datasets.
Further trained alpaca
At this stage, since we have build the training and deploy process. We optimized the model in twofolds, training the model with more data, then scaling up the model to more parameters.
Trained with more data
Thanks to Alpaca-CoT's detailed dataset cellection. We desided to improve the model's reasoning (COT), coding, dialog, and Chinese performance. So we fine tuned the model with the following dataset:
This section presents the performance comparitions between the reproduced Stanford Alpaca 7B and the self-fine tuned 7B model. And the results show the fine tuned model has a big improvement on the reasoning (COT), coding, dialog, and Chinese abilities.
And we can say, with a corresponding dataset, we can achieve better performances on any field/tasks.
Scale up model
Then we scale up the model from 7B to 13B and 30B.
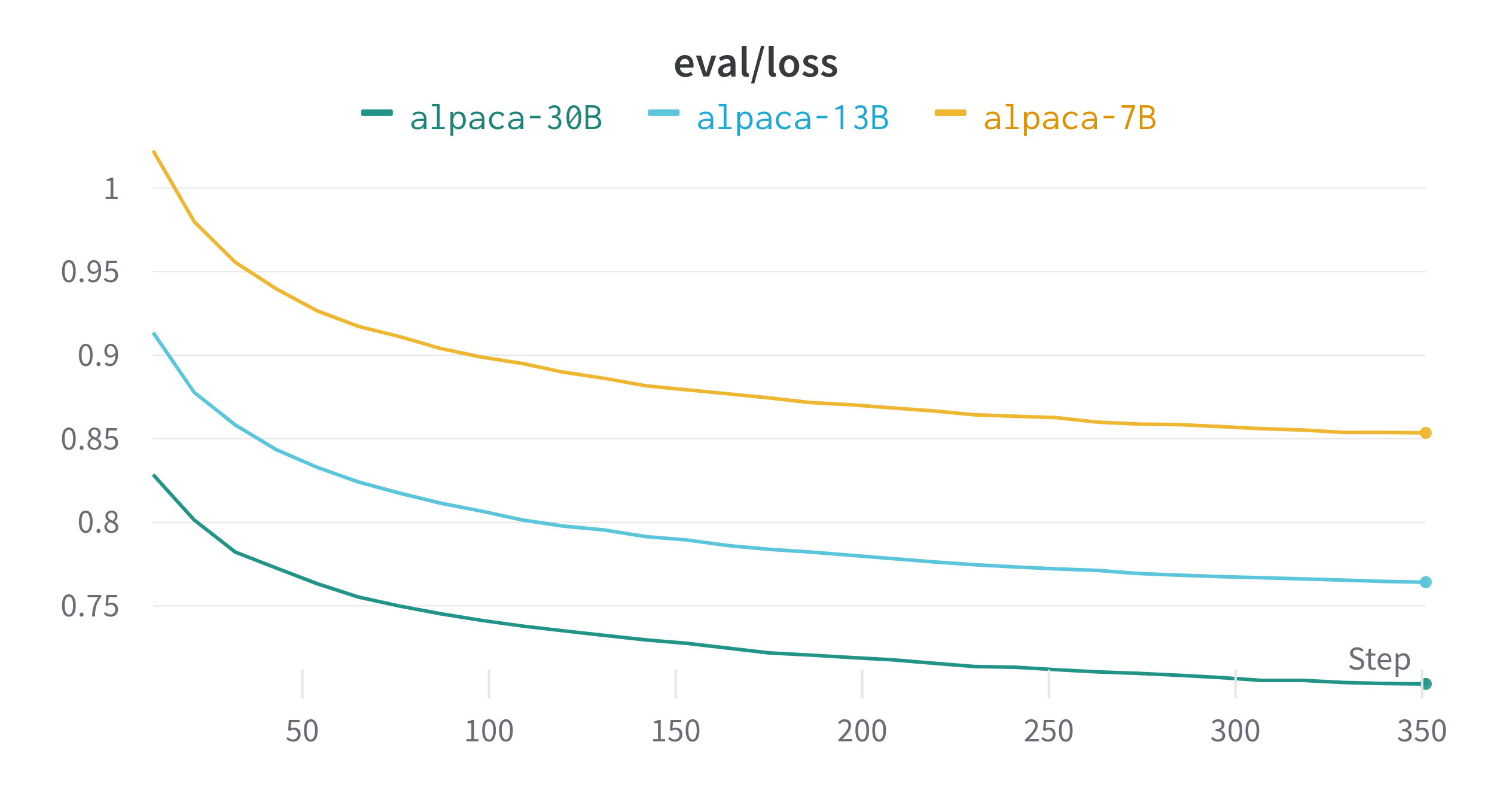
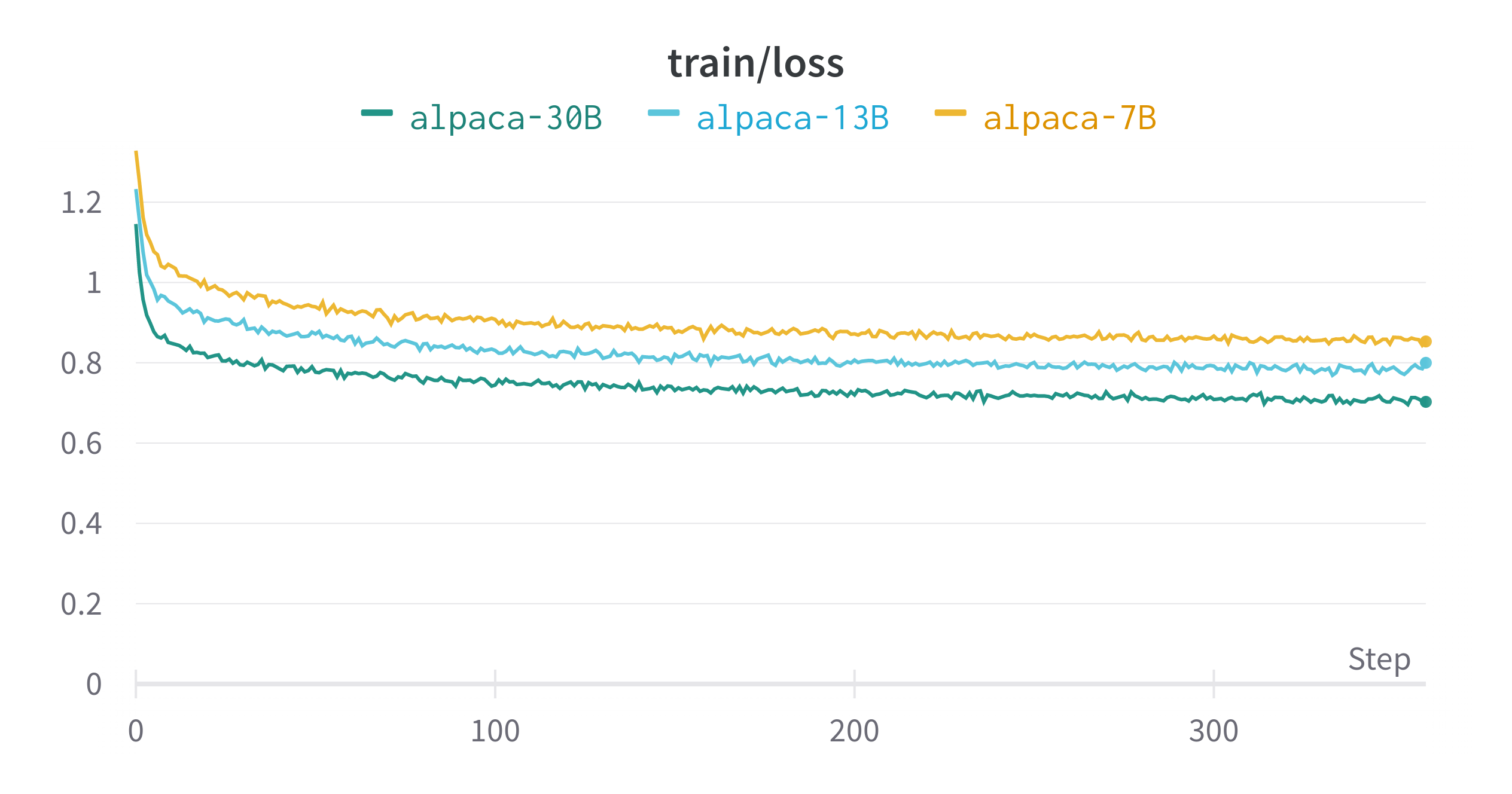
A brief summery of results process is shown below:
 |
 |
|---|
| 7B | 13B | 30B | |
|---|---|---|---|
| Duration | 10h 37m 26s | 17h 49m 37s | 1d 3h 23m 7s |
| train loss | 0.8531 | 0.7999 | 0.7159 |
| eval loss | 0.8534914255142212 | 0.7641683220863342 | 0.7117758989334106 |
A detailed evaluation across a large range of tasls among these models and with the ChatGPT's answers are shown here.
The result shows that our AI language model has been performing well after scaling up to 30B parameters. The 30B parameters version is better than the 7B parameters version, but it is still not as well as ChatGPT, especially on text generation tasks and safety tasks.
Possible applications
Refer to this blog.
References
The icons and images from FlatIcon and created by midjouney
Original front-end run27017/vue-chat.
LLaMA github (facebookresearch/llama)
alpaca dataset, yahma/alpaca-cleaned
- LLaMA: Open and Efficient Foundation Language Models ↩︎
- Unofficial Llama Discord 😁 · Issue #158 · facebookresearch/llama · GitHub ↩︎
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971. ↩︎