Improve the chatbot
The process to further improve the current alpaca model with larger datasets.
Dataset
First of all, a big thank to Alpaca-CoT for collecting and formatting such a detailed dataset. And a great training framework for efficient training process.
I desided to further improve current model alpaca 7B/13B in 2 steps:
- First step we test for our training process, take a small dataset to improve stories, Chinese, and COT performance
- alpaca_data_cleaned.json
- CoT_data.json
- belle_data0.5cn.json, refer to BELLE for more details
- Second step, after tuned the superparameters and the training process, we add more dataset, improve the Chinese, dialogue, reasoning, coding performance
- gpt4all_without_p3.json, refer to gpt4all for more details
- belle_data1.0M_cn.json, refer to BELLE for more details
The final dataset results in:
And we combine json files with:
import json
files=['file1.json','file2.json','file3.json']
output_file = 'combined.json'
def merge_JsonFiles(filename):
result = list()
for f1 in filename:
with open(f1, 'r') as infile:
result.extend(json.load(infile))
with open(output_file, 'w') as output_file:
json.dump(result, output_file)
merge_JsonFiles(files)Train steps
step 1:
After setting up the dependencies with:
git clone git@github.com:PhoebusSi/Alpaca-CoT.git
pip install -r requirements.txtFirst we train a small size mode with small size of dataset to validate the training process.
Combine the jsons:
files=['alpaca_data_cleaned.json','CoT_data.json','belle_data05cn.json']Train with
export HF_DATASETS_CACHE="/home/.cache"
torchrun --nproc_per_node 8 \
--nnodes=1 --node_rank=0 uniform_finetune.py \
--model_type llama --model_name_or_path ../llama_weights_converted/7B \
--data alpaca-cot-belle --lora_target_modules q_proj v_proj \
--per_gpu_train_batch_size 128 --gradient_accumulation_steps 32 \
--learning_rate 3e-4 --epochs 1We found durining training, the convergence speed is slow, and the memory usage is not optimized using lora method. As a result we add the learning rate as well as the batch size and per_gpu_train_batch_size.
Second, when deploiying the test model, it still doesn’t know where to stop for each model, and the dialogue performance is poor as well. We decided to change add_eos_token=False to True. And decided to include more dialog related dataset.
Step 2: bigger dataset
At this stage, we only fine tune the 7B model, applying the above measurements, we
combine the jsons:
files=['CoT_data.json','gpt4all_without_p3_formatted.json', 'Vicuna.json', 'belle_data1M_cn.json', 'dialog_w_context/train.json']train with
export HF_DATASETS_CACHE="/home/.cache"
torchrun --nproc_per_node 8 uniform_finetune.py --model_type llama \
--model_name_or_path ../llama_weights_converted/13B \
--data gpt4-cot-belle1M-vicuna-dialog --lora_target_modules q_proj v_proj \
--per_gpu_train_batch_size 32 --gradient_accumulation_steps 1 \
--learning_rate 4.5e-4 --epochs 1 &It takes 1h for data spliting and mapping and 10h 37m 26s for training on 8 NVIDIA A800-SXM4-80GB GPUs. And the training summary is presented in the Appendix.
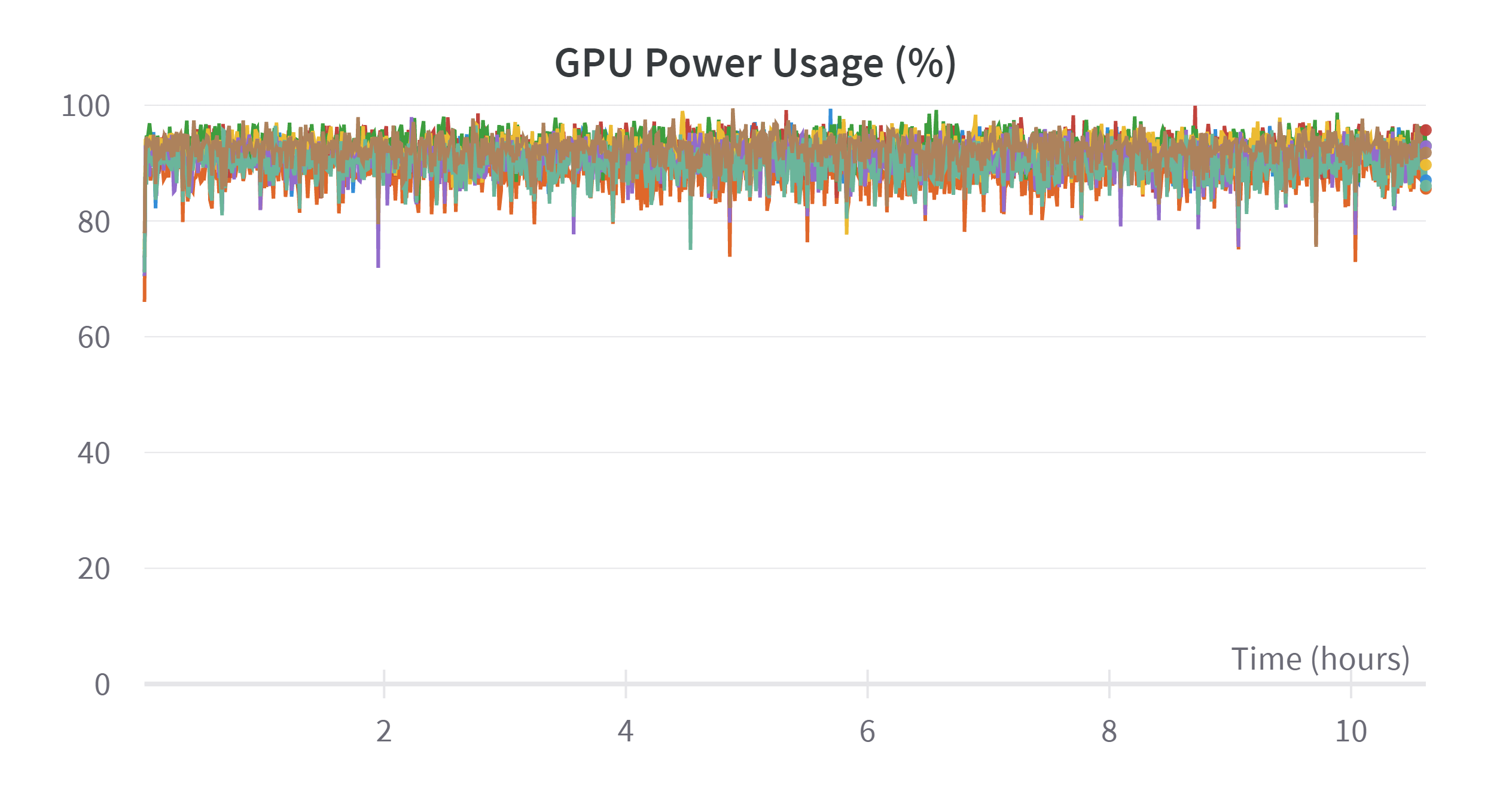
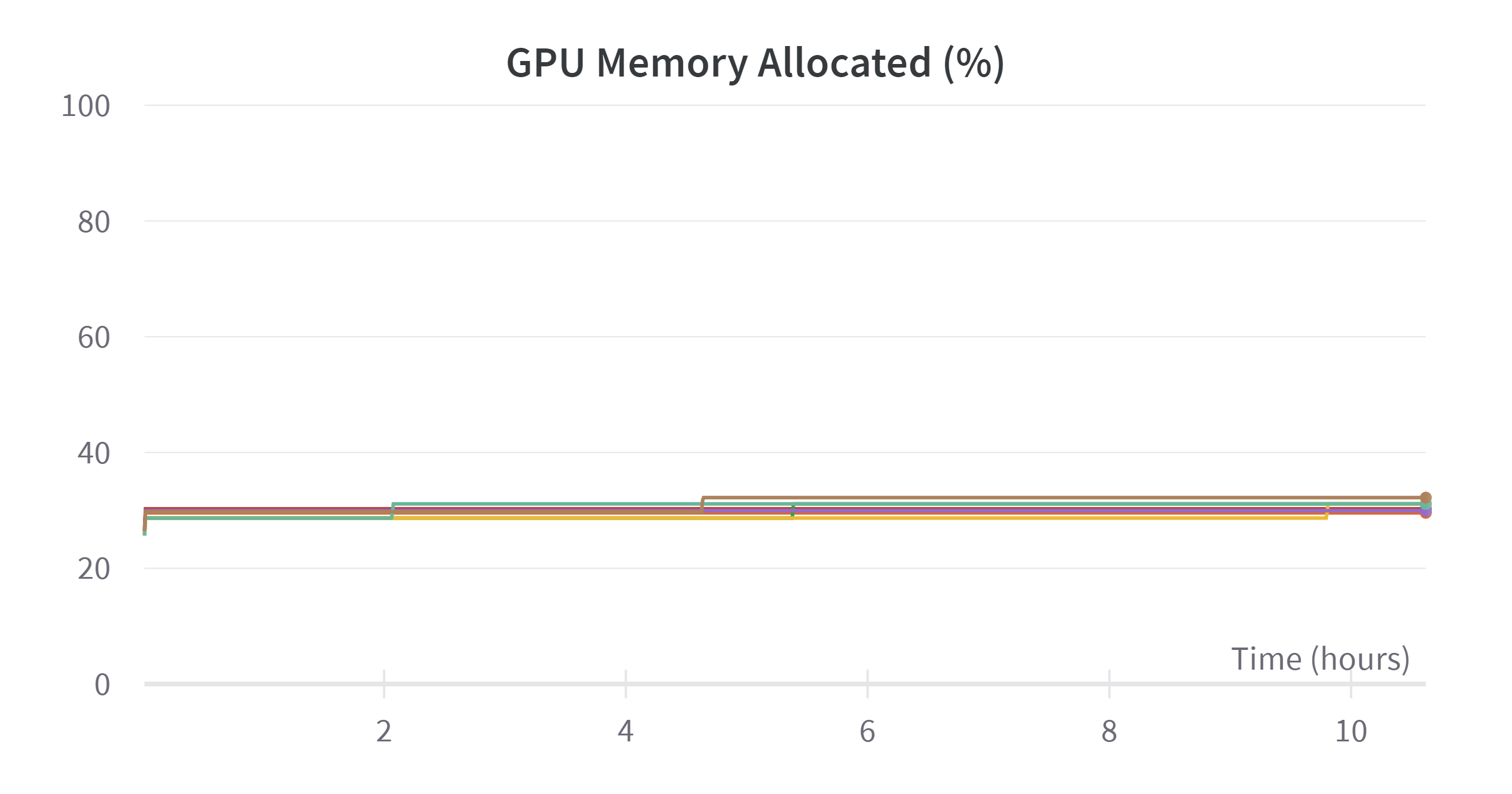
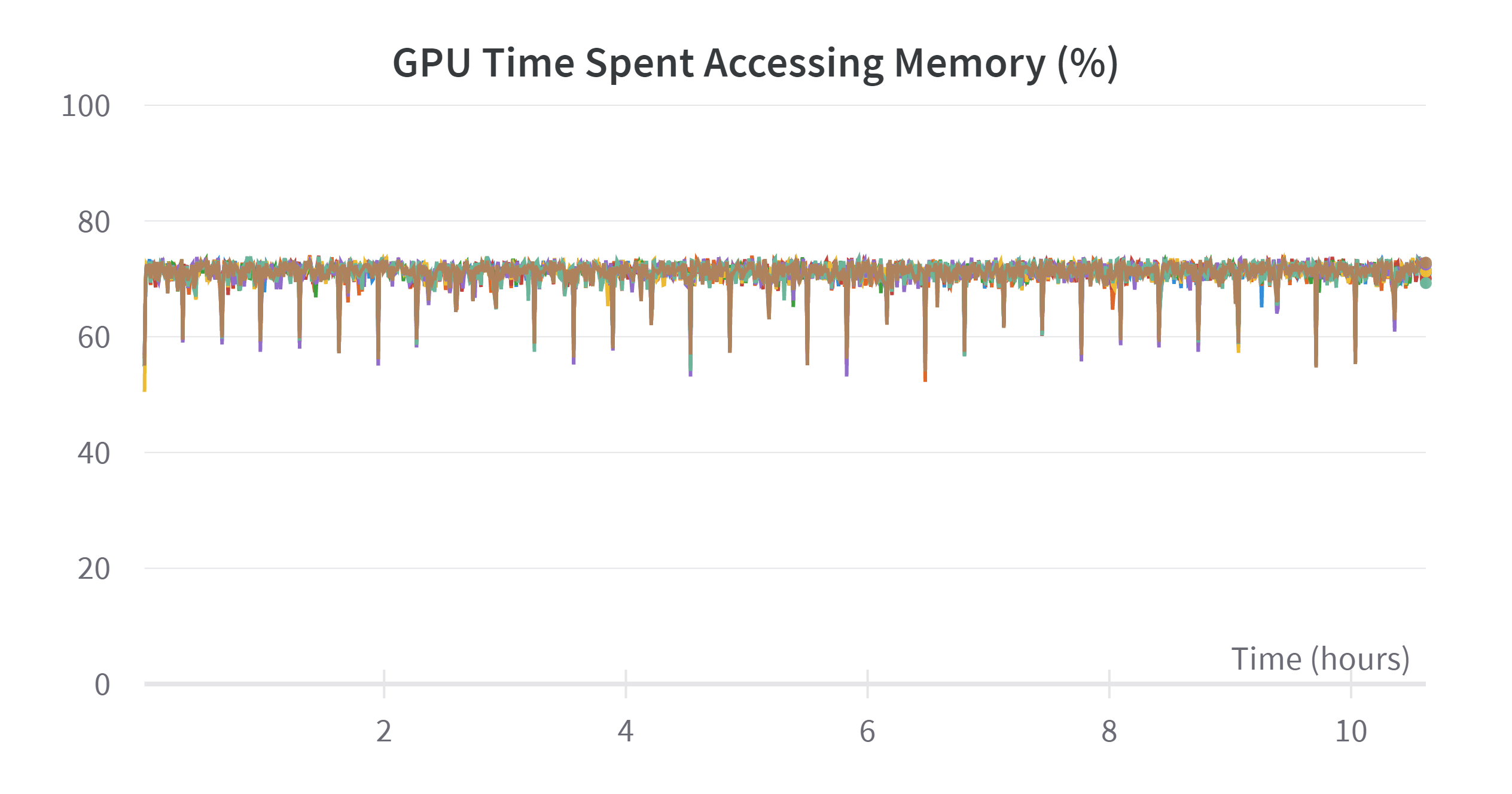
Note that the training process is badly inefficient, refer to the appendix, the memory accessing takes as high as 75% time of training. The high memory accessing problem might because of training 7B on 8 devices is too much. And the low memory usage is because I want to keep to batch size not higher than 256 to get a good generalization ability. But I have no time to do ablation on this super parameter.
Deployment and comparision
We deploy the model with context using the same way as the last section of previous blog.
Actually it is really difficult to evaluate a large language model. Using GPT4 is a possible approach but I don’t have OpenAI plus. So at this stage, I evaluate by myself.
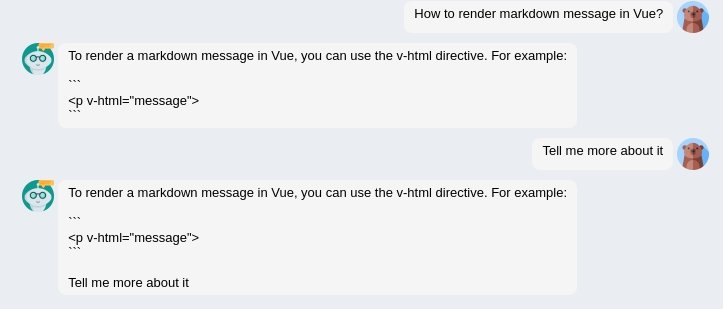
Here are some example results between the further fine tuned model and the alpaca model from precious blog.
python alpaca_backend.py --size 7 --data gpt4-cot-belle1M-vicuna-dialog --bit 1
python alpaca_backend.py --size 7 --data alpaca --bit 1dialog & discourse ability
| Alpaca | Fine tuned alpaca |
|---|---|
 |
 |
Chinese ability
| Alpaca | Fine tuned alpaca |
|---|---|
 |
 |
 |
 |
 |
 |
We can the Chinese ability of fine tuned version shows a big improvement. Impressively, even though Alpaca hasn't been trained in Chinese. It can understand Chinese prompt. As I shown in the first example, when I asked "What is the emergent abilities of LLM[1]?" The Alpaca model gives the model perfectly.
In the second example, when I ask "Introduce Shanghai" in Chinese. The model also clearly understands my instruction and gives me what I want, though in English.
However, the translation ability is still poor. It's too hard for it.
Appendix
| Overview | |
|---|---|
| State | finished |
| Start time | April 6th, 2023 at 4:55:13 pm |
| Duration | 10h 37m 26s |
| Hostname | localhost.localdomain |
| OS | Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.17 |
| Python version | 3.9.12 |
| Python executable | /home/conda/llama/bin/python |
| Command | /home/singleGPU/chatbot/fintune/Alpaca-CoT-main/uniform_finetune.py --model_type llama --model_name_or_path ../llama_weights_converted/7B --data gpt4-cot-belle1M-vicuna-dialog --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 32 --gradient_accumulation_steps 1 --learning_rate 4.5e-4 --epochs 1 |
| System Hardware | |
|---|---|
| CPU count | 56 |
| GPU count | 8 |
| GPU type | NVIDIA A800-SXM4-80GB |
| Train logs: | |
|---|---|
| epoch | 1 |
| global_step | 6573 |
| learning_rate | 9.732735980225552e-7 |
| loss | 0.8531 |
| total_flos | 34166331403636048000 |
| train_loss | 0.8965309444272535 |
| train_runtime | 38249.6774 |
| train_samples_per_second | 43.989 |
| train_steps_per_second | 0.172 |
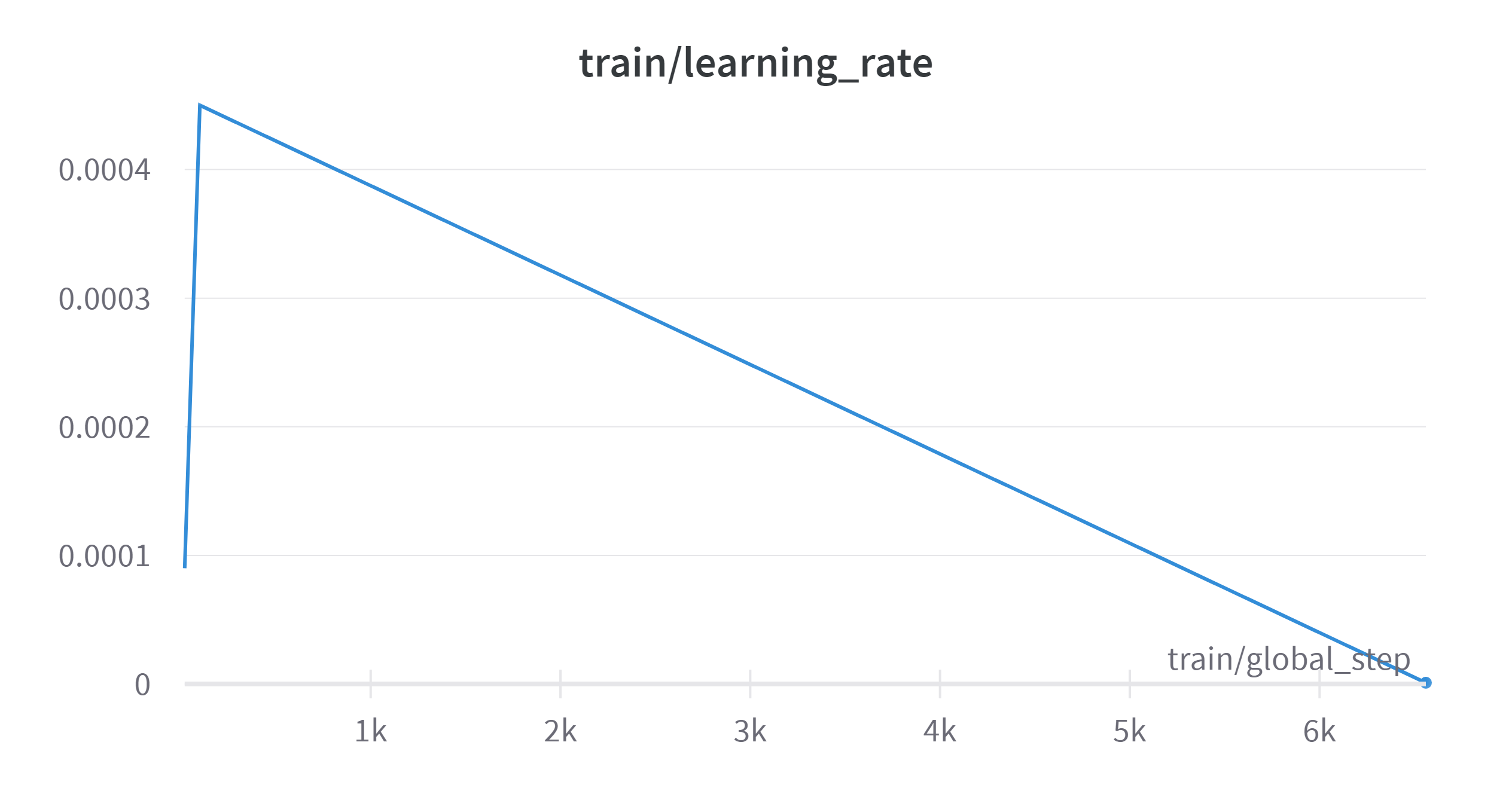
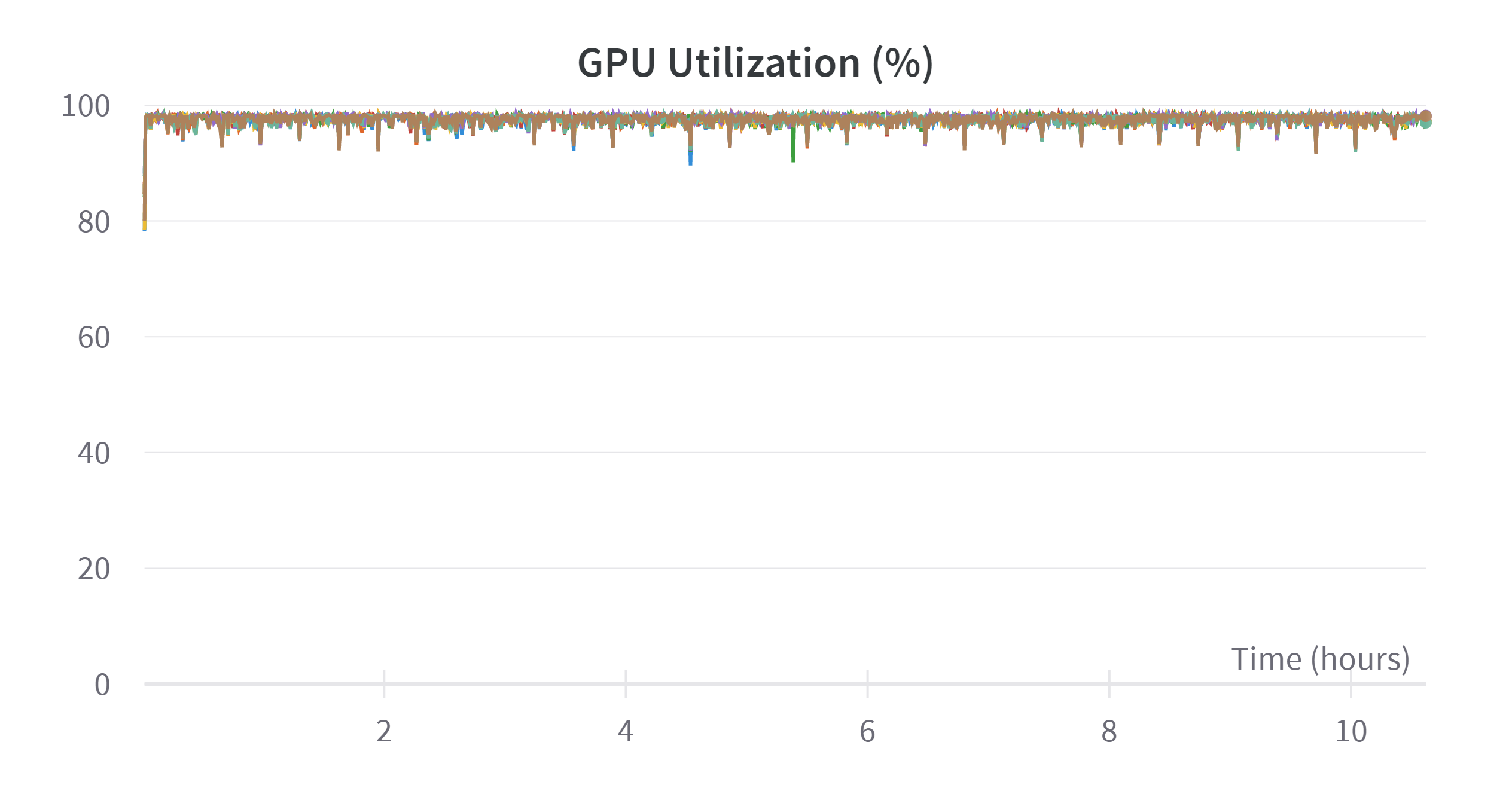
| Training process visualization | |
|---|---|
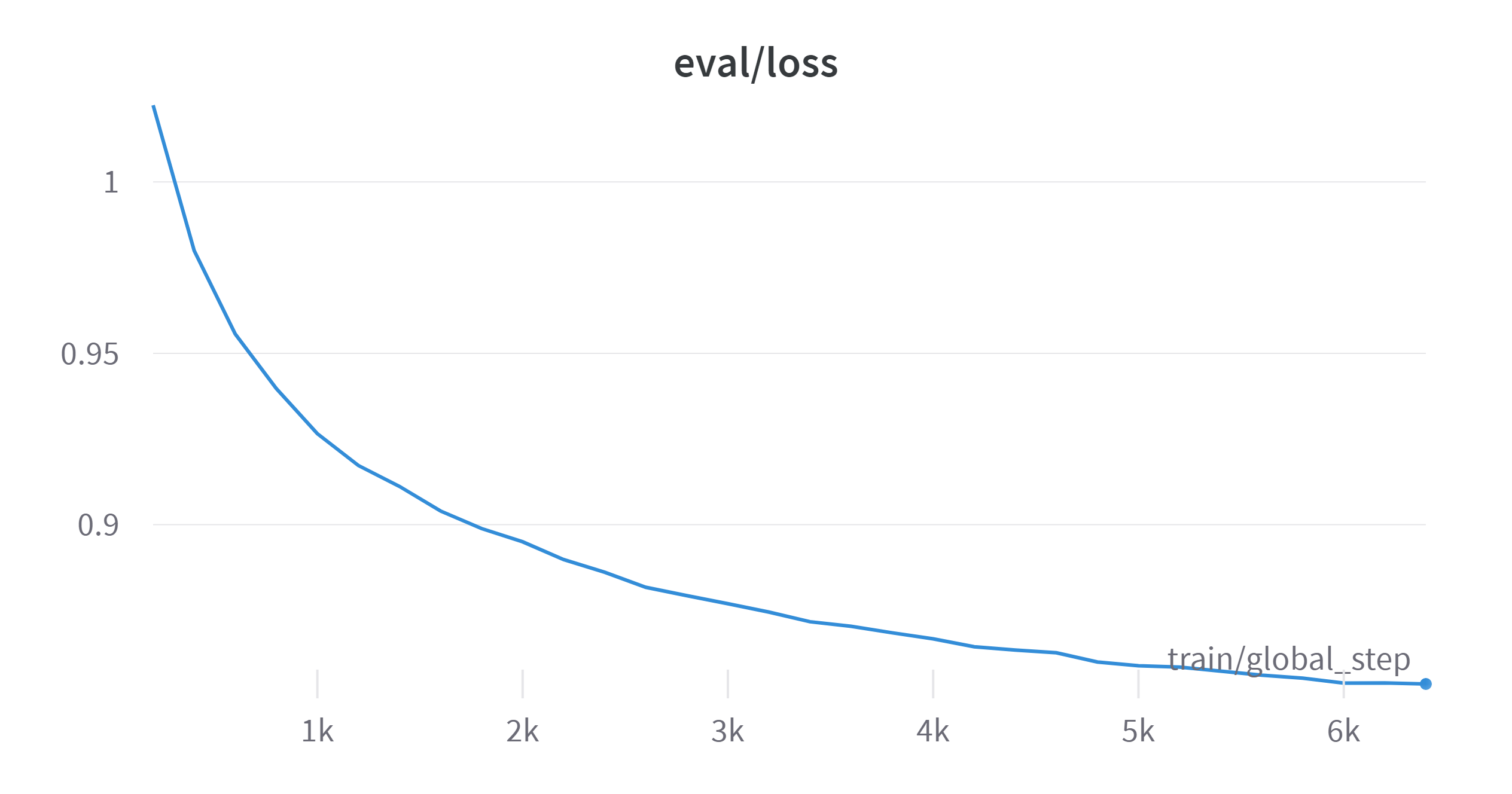 |
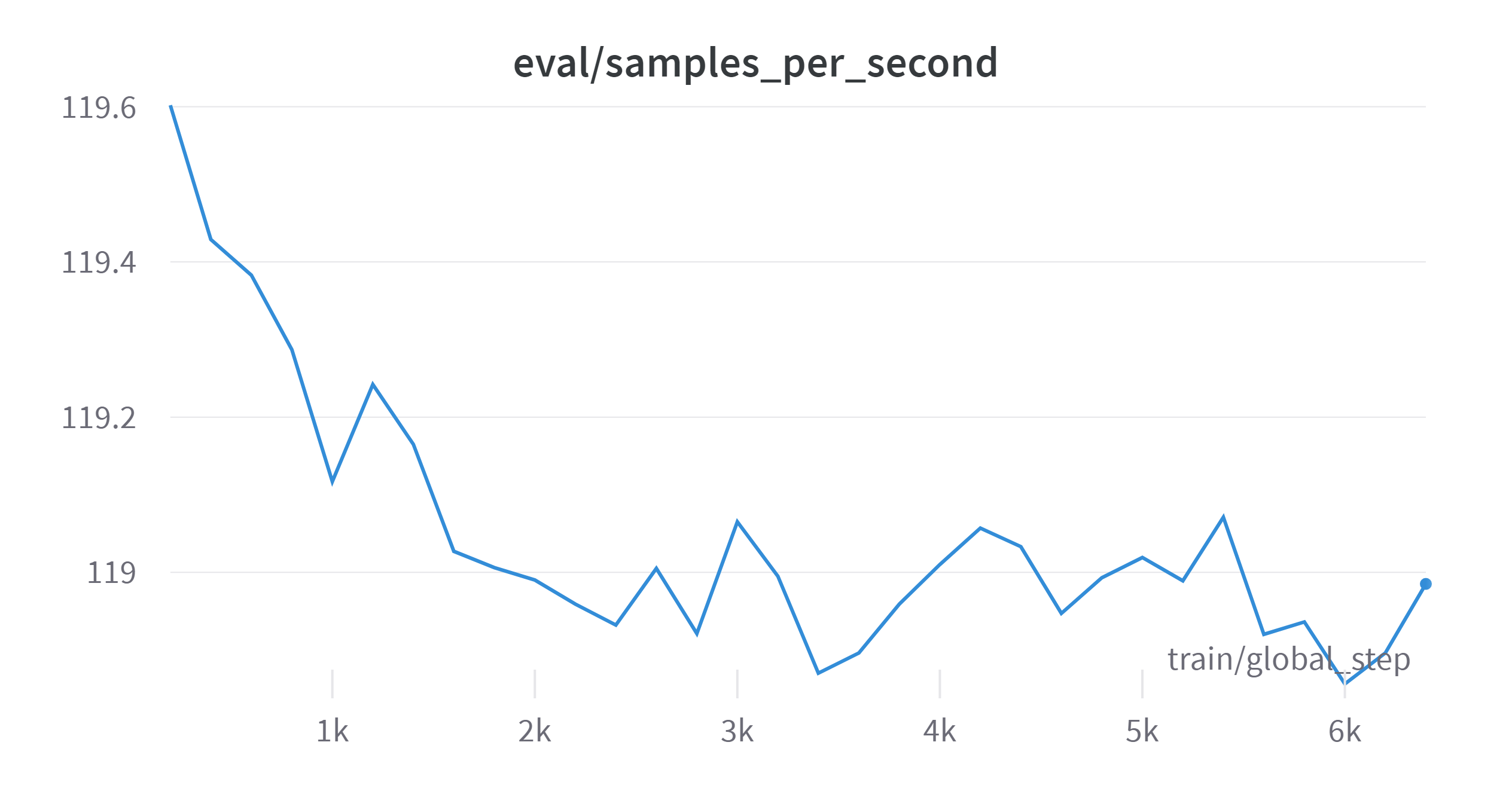 |
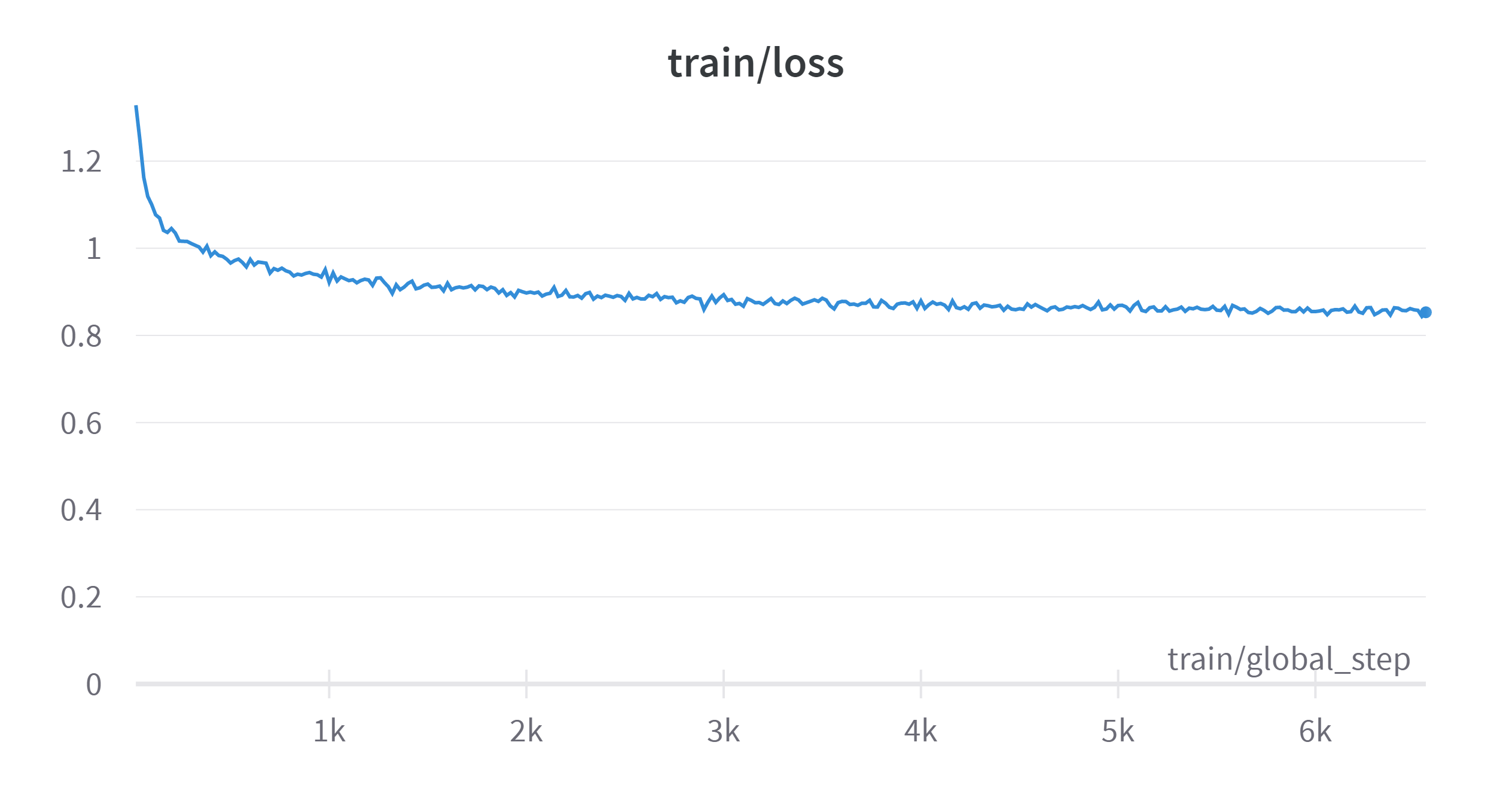 |
 |
 |
 |
 |
 |
References
Belle: LianjiaTech/BELLE
alpaca COT: PhoebusSi/Alpaca-CoT
alpaca COT dataset: Alpaca-CoT