Chinese chatbot summary
A collection of recent models variants from llama/alpaca that can be considered later, including the Chinese chatbot.
Extra! Extra!
The llama and alpaca model has been a very popular topic in the research community, along with the increasing attention of ChatGPT and GPT4 for the mainstream. I see interesting and promising llama/alpaca variants every single day. Here are a collection of them:
Training with LoRA
Using the Alpaca dataset, the llama model can also be finetuned using low-rank adaptation (LoRA)[1] (see tloen/alpaca-lora).
Alpaca LoRA turned the weights into 8-bit int to reduce the memory requirement, accerlate its training and inferencing, which allows the 7B model to be trained within 6 hours on a single RTX 4090.
The authors claim that
Without hyperparameter tuning, the LoRA model produces outputs comparable to the Stanford Alpaca model.
And they’ve posted a comparision among Stanford Alpaca 7B, Alpaca-LoRA 7B, and text-davinci-003. I beleive them after reading this.
Deploy it on CPU!
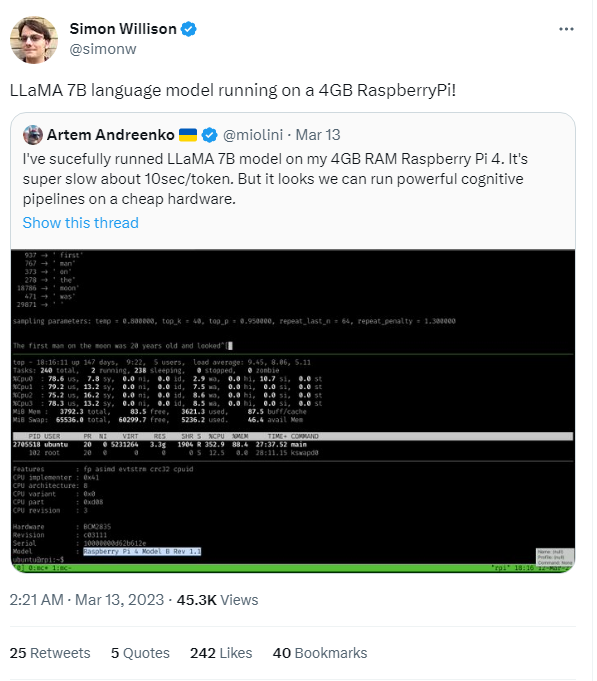
Besides, the community has tried many ways to consolidate the memory requirements and deploy llama/alpaca on different devices. Such as a different GPU architecture jankais3r/LLaMA_MPS, CPUs ggerganov/llama.cpp, antimatter15/alpaca.cpp, or even Raspberry Pi 4GB #58 (as slow as 10s/token but very impressive).
However, considering there are not many researches on how much the performance deteriation is compared with the origianl large model, and llama.cpp have been hacked before. And considering we still have 8*A800 80GB at least for now. So we are not considering try these. But maybe later.
Vicuna
Vicuna is created by fine-tuning a LLaMA base model using approximately 70K user-shared conversations gathered from ShareGPT.com with public APIs. And the authors use GPT4 to evaluate Vicuna along with other trending LLMs and shows a very similar performance to chatGPT and Bard.
| Baseline | Baseline Score | Vicuna Score |
|---|---|---|
| LLaMA-13B | 513.0 | 694.0 |
| Alpaca-13B | 583.0 | 704.0 |
| Bard | 664.0 | 655.5 |
| ChatGPT | 693.0 | 638.0 |
And it has been seen that Vicuda has a better Chinese performance even though they don't have trained specifically on Chinese dataset.
GPT4all
Just days before, nomic-ai published their own finetuning version of llama, with a Discord demo and a Technical Report[2]. Even if it has only 3 pages, it provides more information than the 99-page GPT4 technical report [3].
Chinese alpaca
And also, ymcui/Chinese-LLaMA-Alpaca just came to me yestoday when I was thinking of how to translate the alpaca data into Chinese (One guy on the Youtube did a calculation of the estimated cost on tranlating the whole 52K instructions and answers into Genmaney. It would cost about $500 on the Deepl API, or Google translate API.)
Chinese alpaca takes a different route, instead of doing instrcuction fine tuning, they retrained the llama first.
This repo solves my probelm because it provides the translated data, and the lora weights trained on this data.
BELLE
Furthermore, aligning with alpaca’s data generation method, BELLE generates a Chinese dataset with instructions and answers of ChatGPT. They also did a great ablation experiments on how large improvements the model can benefit from different size of Chinese dataset(0.2M, 0.6M, 1M, 2M).
Overall, increasing the amount of data consistently improved performance, but the extent of improvement varied across different types of tasks. For Extract, Classification, Closed QA, and Summarization tasks, increasing data continued to improve performance without reaching a plateau. For Translation, Rewrite, and Brainstorming tasks, good performance could be achieved with only hundreds of thousands of data. However, for Math, Code, and COT tasks, these models' performance were poor, and increasing data did not lead to further improvement.
More of it see their arxiv paper[4].
They also published two datasets that in the same format of the alpaca dataset. see train_1M_CN and train_0.5M_CN.
Alpaca COT
Another extension that claims to improve its Chinese is capability is PhoebusSi/Alpaca-CoT, they extend the alpaca dataset, adding Chinese and CoT instructions.
And they have collected all the useful dataset here Alpaca-CoT
- This repo contains code, modified from here, which can *finetune LLaMA cheaply and efficiently* (without performance degradation compared to Stanford Alpaca) by using low-rank adaptation (LoRA) [4], PEFT and bitsandbytes. The
7b,13band30bversions of LLaMA models can be easily trained on a single 80G A100.- The models published in this repo significantly *improve the CoT (reasoning) capability*.
- The models published in this repo significantly *improve the ability to follow Chinese instructions*.
- This repo contains *a collection of instruction-finetuning datasets that are continuously collected*, which so far includes English, Chinese and CoT instructions. In addition, a collection of checkpoints trained with various instruction datasets is also provided.
So the title is not complete missleading because it is very promising to reproduce above models.
References
Alpaca lora: tloen/alpaca-lora
llama.cpp: ggerganov/llama.cpp
Alpaca.cpp: antimatter15/alpaca.cpp
Alpaca MPS: jankais3r/LLaMA_MPS
Vicuda blog: Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
Chinese llama alpaca: ymcui/Chinese-LLaMA-Alpaca
BELLE: LianjiaTech/BELLE
alpaca COT: PhoebusSi/Alpaca-CoT
alpaca COT dataset: Alpaca-CoT
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685. ↩︎
- GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo ↩︎
- GPT-4 Technical Report ↩︎
- Ji, Y., Deng, Y., Gong, Y., Peng, Y., Niu, Q., Zhang, L., ... & Li, X. (2023). Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases. arXiv preprint arXiv:2303.14742. ↩︎