CUDA Programming 1
Basic CUDA programming methods, with a simple matrix multiply example constructed from the scratch.
All the pics and contents are not original. The contents of the whole series are mainly collected from:
Introduction
CPU Computing History: APIs
2001/2002 - researchers see GPU as data-parallel coprocessor
The GPGPU field is born, expand GPU to the general computing
2007 - NVIDIA releases CUDA
- CUDA Compute Uniform Device Architecture
- GPGPU shifts to GPU Computing
2008 - Khronos releases OpenCL specification
2013 - Khronos releases OpenGL compute shaders
2015 - Khronos releases Vulkan and SPIR-V
• Except for SoC
• CUDA Program
• Contains both host and device code
CUDA Terminology
- Host - typically the CPU
- Code written in ANSI C, or other languages
- Device typically the GPU (data-parallel)
- Code written in extended ANSI C, or fortran
- Host and device have separate memories
- Except for SoC ( System On a Chip, Unified Memory Architecture )
- CUDA Program
- Contains both host and device codes
Kernel
A CUDA Kernel represents a data-parallel function
- Invoking a kernel creates lightweight threads on the device
- Threads are generated and scheduled with hardware
- similar to a shader in OpenGL/WebGL/VuIkan.
Example
Execute \(C = A+B\) in N times in parallel by N different CUDA threads
// Kernel Defination
__global__ void vectorAdd(const float* A, const float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// ...
// Kernel invocation with N threads
vectorAdd<<<1, N>>>(A, B, C)
}__global__ |
Declaration specifier |
threadIdx.x |
Thread Index |
<<<1,N>>> |
Kernel execution configuration |
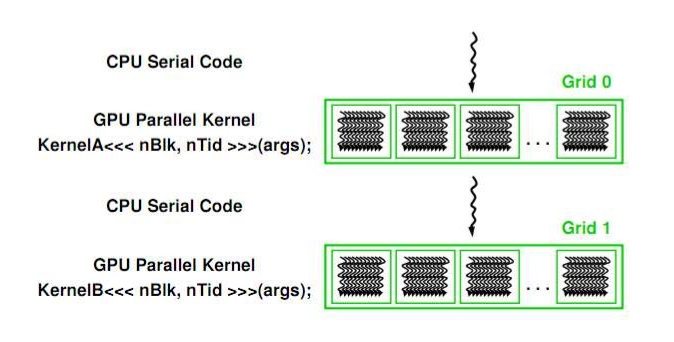
CUDA Program Execution
When a CUDA program is executed, a serial code will run on the host until the Kerenl invocation. Then the parallel code runs on the devices. The resultant data is gathered back to the host to run on serial...
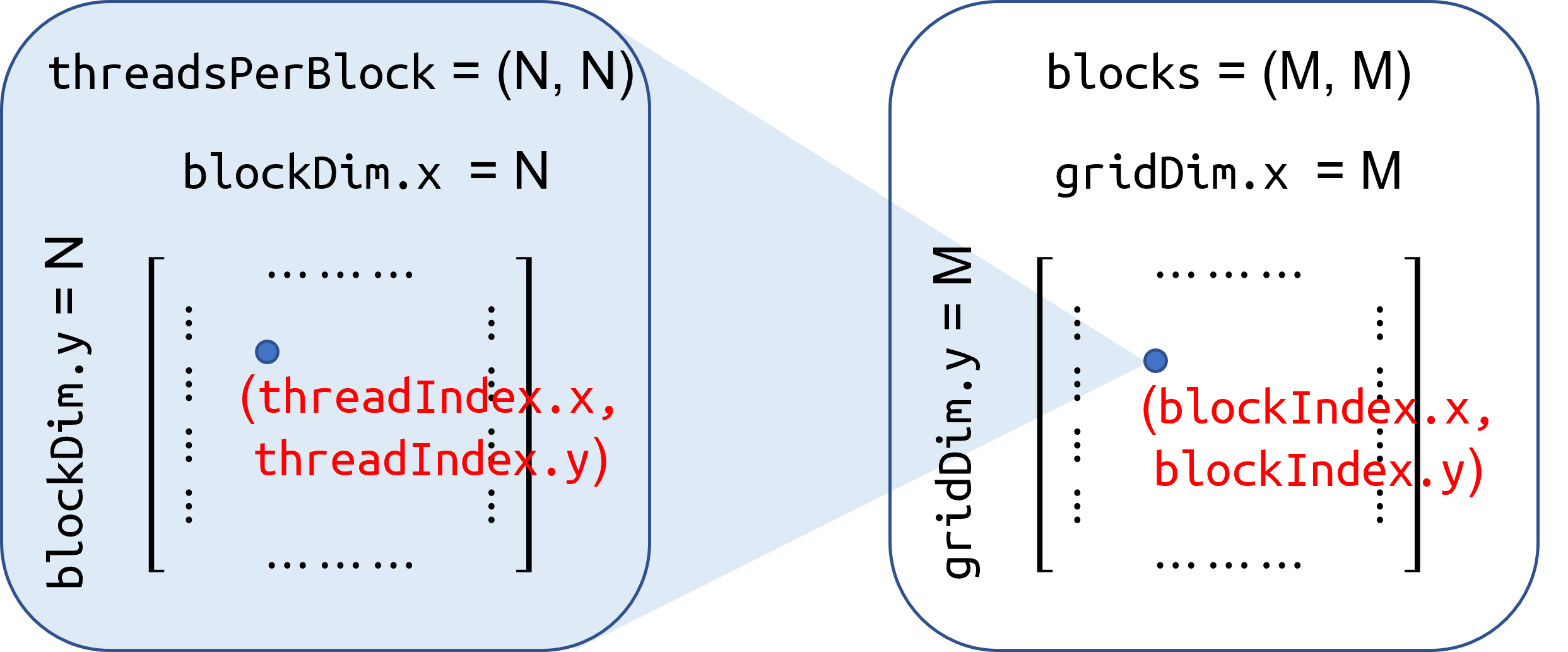
Thread Hierarchies
Grid - one or more thread blocks
- 1D, 2D or 3D
- Example: Index into vector, matrix, volume, better for representing arrays in 2D and 3D
Block - array of threads
- 1D, 2D, or 3D
- Each block in a grid has the same number of threads
- Each thread in a block can
- Synchronize
- Access to the shared memory hazard-free
Two threads from two different blocks cannot cooperate
Thread ID, one block
Thread ID: Scalar thread identifier
Thread Index: threadIdx
- 1D: Thread ID == Thread Index
- 2D with size (Dx, Dy)
- Thread ID of \(index_{(x, y)} = x + Dim_x * y\)
- 3D with size (Dx, Dy, Dz)
- Thread ID of \(index_{(x, y,z)} = x + Dim_x * y + Dim_x * Dim_y * z\)
example
// Kernel Definition
__global__ void matrixAddition(const float* A, const float* B, float* C)
{
// 2D Thread Index to 1D memory index
int idx = threadIdx.y * blockDim.x + threadIdx.x;
C[idx] = A[idx] + B[idx];
}
int main()
{
// ....
// Kernel invocation with one block of N * N * 1 threads
int blocks = 1;
dim3 threadsPerBlock(N, N); // N rows x N columns
// 1 block, 2D block of threads
matrixAddition<<<blocks, threadsPerBlock>>>(A, B, C);
}Here, blockDim is an array with 2 elements representing the dimension of thread matrix inside the block.

Group of threads
- G80 and GT200: Up to 512 threads
- Fermi, Kepler, Maxwell, Pascal: Up to 1024 threads
Locate on same processor core (SM)
Share memory of that core (SM)
Thread ID, multiple blocks
1D or 2D Grid
Block Index: blockIdx
example
// Kernel Definition
__global__ void matrixAddition(const float* A, const float* B, float* C)
{
// 2D Thread Index to 1D memory index
int blockId_2D = blockIdx.y * gridDim.x + blockIdx.x +;
int threadId_2D = threadIdx.y * blockDim.x + threadIdx.x;
int idx = blockId_2D * (blockDim.x * blockDim.y) + threadId_2D;
C[idx] = A[idx] + B[idx];
}
int main()
{
// ....
// Kernel invocation with computed configuration
dim3 threadsPerBlock(N, N); // N*N threads per block
dim3 blocks(M, M); // M*M blocks per thread
// 2D grid of blocks, 2D block of threads
matrixAddition<<<blocks, threadsPerBlock>>>(A, B, C);
}
Group of blocks
Blocks execute independently
- In any order: parallel or series
- run whenever one block is ready
- Scheduled in any order by any number of cores
- Allows code to scale with core count
- For example, with 8 blocks on a GPU with 2 cores(SM), 2 blocks are run in parallel each time. If with a GPU with 4 cores, 4 blocks are run in parallel each time.
- Allows code to scale with core count
CUDA Memory Transfers
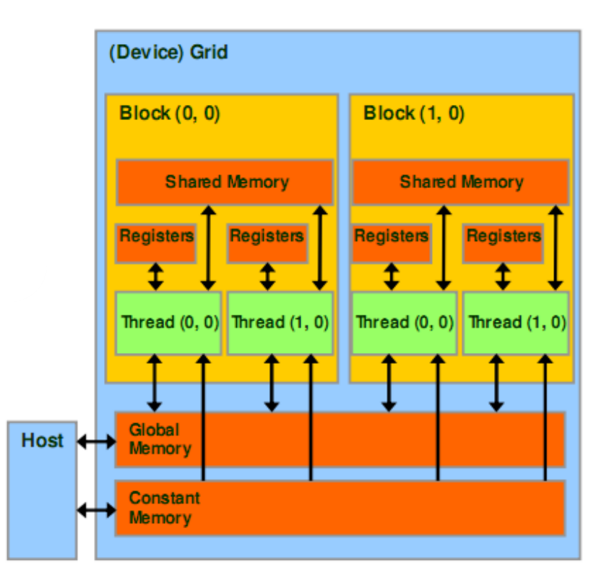
Memory Accesibility
| Device code can: | Host code can: |
|---|---|
| R/W per-thread registers | |
| R/W per-thread local memory | |
| R/W per-block shared memory | |
| R/W per-grid global memory | R/W per-grid global memory |
| Read only per-grid constant memory | R/W per-grid constant memory |
| Read only per-grid texture memory | R/W per-grid texture memory |
Memory transfers
Host can transfer to/from device, through PCIE I/O
- Global memory
- Constant memory
cudaMalloc()
- Allocate global memory on device
cudaFree()
- Frees memory
Example
float *deviceMemory = NULL; // Pointer to device memory
int size = width * height * sizeof(float); // size in bytes
cudaMalloc((void**)&deviceMemory, size); // Allocate memory
// Do work
cudaFree(deviceMemory); // Free memoryNot that (void**)&deviceMemory is on device, not on host. Cannot be used by host directly. (a little bit contradict with the concept of global memory, need check later)
cudaMemcpy()
Cuda-Memory-Copy, transfer memory between host and device
Host to host
cudaMemcpy(destPtr, sourcePtr, size, cudaMemcpyHostToHost);Host to device
cudaMemcpy(devicePtr, hostPtr, size, cudaMemcpyHostToDevice);(destination(host), source(device), size in byte, copy direction)
Device to host
cudaMemcpy(hostPtr, devicePtr, size cudaMemcpyDeviceToHost);Device to device
cudaMemcpy(destPtr, sourcePtr, size, cudaMemcpyDeviceToDevice);
Example: matrix multiply
\[ \mathbf{P} = \mathbf{M}\mathbf{N} \]
\(\mathbf{P,M,N}\) are all square matrices with the same width.
CPU implementation
void MatrixMultiplyOnHost(float* M, float* N, float* P, int width)
{
for (int i = 0; i < width; ++i)
{
for (int j = 0; j < width; ++j)
{
float sum = 0;
for (int k = 0; k < width; ++k)
{
float a = M[i * width + k];
float b = N[k * width + j];
sum += a * b;
}
P[i * width + j] = sum;
}
}
}GPU implementation
CUDA skeleton
This is a general framwork that is suitable for all most all the CUDA programs
int main() {
// 1. Allocate and Initialize M, N, and result P matrices
// Copy M, N matrices to device
// 2. M * N on device
// 3. Copy P matrix to host and output
// Free device memory and clean up
return 0;
}Fill up the skeleton
Step 1: Add CUDA memory transfers to the skeleton
void MatrixMultiplyOnDevice(float* hostP,
const float* hostM, const float* hostN, const int width)
{
int sizeInBytes = width * width * sizeof(float);
float *devM, *devN, *devP;
// Allocate M and N on device
cudaMalloc((void**)&devM, sizeInBytes);
cudaMalloc((void**)&devN, sizeInBytes);
// Allocate P
cudaMalloc((void**)&devP, sizeInBytes);
// Copy M and N from host to device
cudaMemcpy(devM, hostM, sizeInBytes, cudaMemcpyHostToDevice);
cudaMemcpy(devN, hostN, sizeInBytes, cudaMemcpyHostToDevice);
// Call the kernel here - Look back at these lines in step 3 later
// Setup thread/block execution configuration
dim3 threads(width, width);
dim3 blocks(1, 1);
// Launch the kernel
MatrixMultiplyKernel<<<blocks, threads>>>(devM, devN, devP, width)
// Copy P matrix from device to host
cudaMemcpy(hostP, devP, sizeInBytes, cudaMemcpyDeviceToHost);
// Free allocated memory
cudaFree(devM); cudaFree(devN); cudaFree(devP);
}Step 2: Implement the kernel in CUDA C
__global__ void MatrixMultiplyKernel(const float* devM, const float* devN,
float* devP, const int width)
{
// Accessing a Matrix, use 2D threads
int tx = threadIdx.x;
int ty = threadIdx.y;
// Initialize accumulator to 0
float pValue = 0;
// Multiply and add
for (int k = 0; k < width; k++)
{
float m = devM[ty * width + k];
float n = devN[k * width + tx];
pValue += m * n;
// no need synchronization for this code
}
// Write value to device memory
// each thread has unique index to write to
devP[ty * width + tx] = pValue;
}Step 3: Invoke the kernel
Look back at the code Call the kernel here in Step1:
// Call the kernel here - Look NOW
// Setup thread/block execution configuration
dim3 threads(width, width);
dim3 blocks(1, 1); // 1 block
// Launch the kernel
MatrixMultiplyKernel<<<blocks, threads>>>(devM, devN, devP, width)Analysis of the example
One Block of threads compute matrix
devP- Each thread computes one element of
devP
- Each thread computes one element of
Each thread
- Loads a row of matrix
devM - Loads a column of matrix
devN - Perform one multiply and addition for each pair of
devManddevNelements - Compute to off-chip memory access ratio close to 1:1 (not very high, load-store intense)
- Loads a row of matrix
Size of matrix limited by the number of threads allowed in a thread block
The performance bottleneck is:
- bandwidth - the heavy memory access