CPU architecture
This is a very quick review on the CPU's fundamentals, in order to compare with GPU's when learning CUDA.
All the pics and contents are not original. The contents of the whole series are mainly collected from:
Outline:
| 中文 | English term |
|---|---|
| 流水线 | Pipelining |
| 分支预测 | Branch Prediction / Speculation |
| 超标量 | Superscalar |
| 乱序执行 | Out-of-Order(OoO) Execution |
| 存储器层次 | Memory Hierarchy |
| 矢量操作 | Vector Operations |
| 多核处理 | Multi-Core |
CPU Introduction
What is CPU: Machine processing instructions.
Example of types of CPU instructions?
arithmetic:
add r3,r4 -> r4load-store:
load [r4] -> r7sequencing/control:
jz end
Aim to be optimized:
\[ \frac{cycles}{instructions} \times \frac{seconds}{cycle} \]
cycles per instructions(CPI) times time per cycle.
cycle: 时钟周期
These two parameters are not independent, need trade-off.
CPU programs:
- light threaded
- heavy memory access
- heavy branches
very less arithmetic instructions.
CPU structure
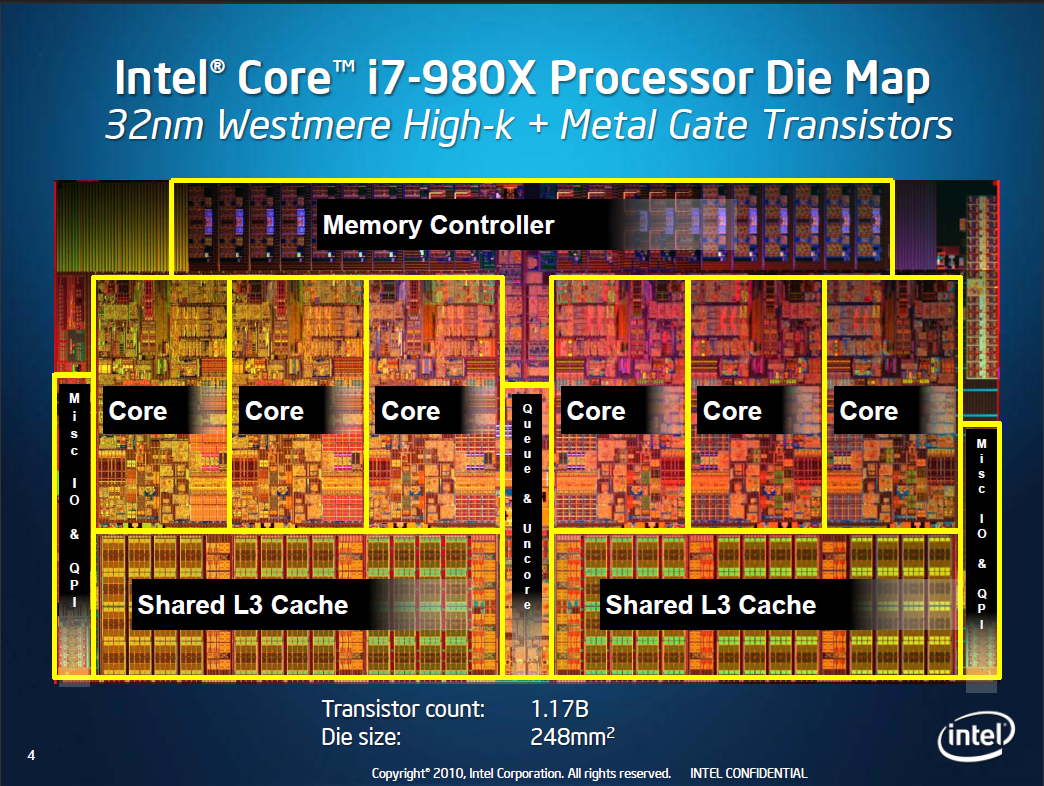
- Very large memory size (Shared L3 Cache)
- Controller (Memory Controller) - also for memory
- less calculators (Core)
CPU related parallelisms
- Instructional level parallelism (ILP) (will talk about it very soon)
- Superscalar
- Out-of-Order
- Data-level parallelism (DLP)
- vectors
- Thread-level parallelism (TLP)
- simultaneous multithreading (SMT)
- multicore
Pipelining
Introduction
Standard 5-stage pipeline:
Fetch-->Decode-->Execute-->Memory-->Writeback
取址-->译码-->执行-->访存-->写回
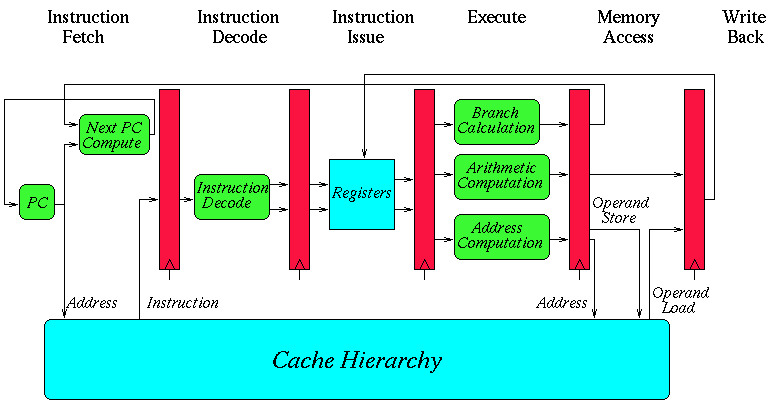
instruction-level parallelism (ILP)
√ reduce clock period
× more latency and area
? dependent instructions -- Bypassing, Stall and OoO
? branching -- Branch Prediction / Branch Predication
? alleged pipeline lengths
- Core - 14, Pentium 4 (Prescott) - >20, Sandy Bridge - medium
Increase ILP: Superscalar, scheduling, out-of-order
Bypassing
sub R2, R3 -> R7
add R1, R7 -> R2execute line 2 immediately after execute line 1, not until finishing of Memory and writeback of line1.
Stall
load [R3] -> R7
add R1, R7 -> R2line 2 can only execute until the finishing of Memory and writeback of line1. The program have to wait.
Branches
jeq loopprediction of how the branch will go, or predication.
Branches
Branch Prediction
Guess what's next, based on branch history.
Modern predictors >90% accuracy
√ Raise performance and energy efficiency
× Area increase and potentially latency (need time for guessing)
Branch Predication
Calculate results for all the conditions
Replace branches with conditional instructions, Avoids branch predictor.
- √ no misprediction
- √ no area increase
- × unnecessary
nop.
GPUs also use predication
Increasing IPC
Superscalar
Normal IPC is limited by the 1 instruction per clock setting.
Superscalar is introduced to increase the pipeline width.
- √ IPC *N
- × Increase Area
- resources *N
- number of bypassing networks *N^2
- more registers and memory bandwidth
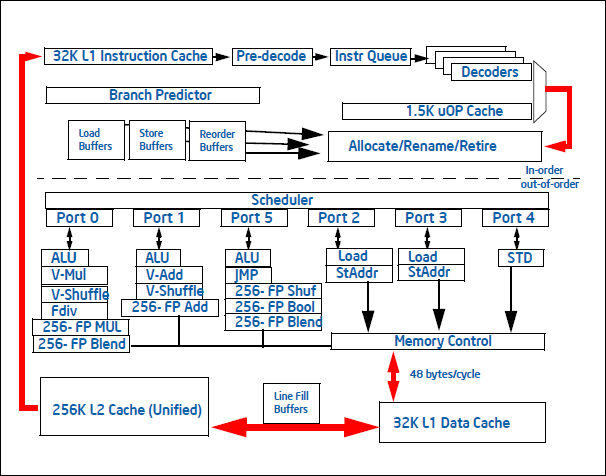
Sandy-Bridge has 6 ports, indicating 6 instructions per clock, managed by Scheduler.
Scheduling
Register Renaming/Aliasing
Check out this piece of code:
xor r1, r2 -> r3
add r3, r4 -> r4
sub r5, r2 -> r3
addi r3, 1 -> r1line 1 and line 2, dependent (Read-After-Write, RAW)
line 3 and line 4, dependent (RAW)
line 1 and line 3 independent (Write-After-Write, WAW), maybe they can execute in parallel, but register r3 is used for both of the lines, can't run in parallel, without any modifications.
So we introduce register renaming to rename r3 into different registers.
xor p1, p2 -> p6
add p6, p4 -> p7
sub p5, p2 -> p8
addi p8, 1 -> p9enable to parallel.
Out-of-Order (OoO) Execution
"Shuffle" the instructions to avoid waiting.
A Journey Through the CPU Pipeline:
Micro-ops can be processed out of order as long as their data is ready, sometimes skipping over unready micro-ops for a long time while working on other micro-ops that are ready. This way a long operation does not block quick operations and the cost of pipeline stalls is greatly reduced.
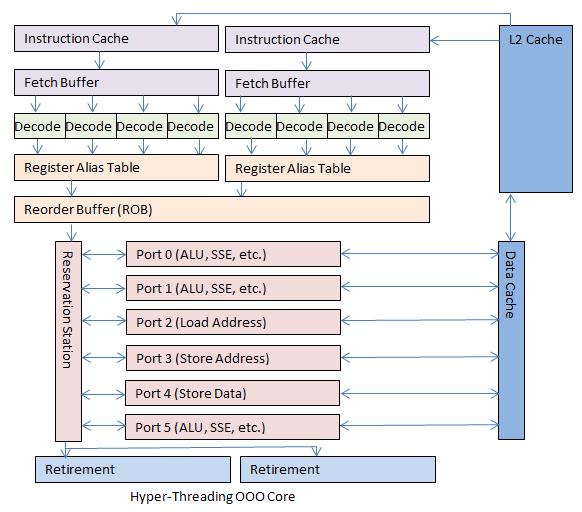
Fetch -> decode -> Rename -> Dispatch -> issue -> register read -> execute -> memory -> writeback -> commit
Devices about OoO include:
- Reorder Buffer (ROB), record all the instructions state on execution.
- Issue Queue/Scheduler, choose next instruction
Advantages and disadvantages:
- √ push IPC nearly to the ideal
- × increase area
- × increase consumption
In-order CPUs: Intel Atom, ARM Cortex-A8, Qualcomm Scorpion
OoO CPUs: Intel Pentium Pro and onwards, ARM Cortex-9 (Apple A5, NV Tegra 2/3), Qualcomm Krait
OoO is not available on some phones, which need area and low consumption
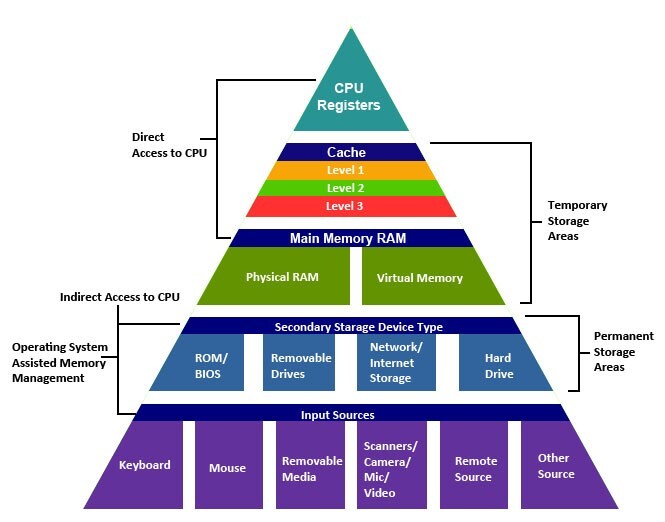
Memory Hierarchy
The bigger the memory, the slower it is, more delay it has.
| Memory type | latency | bandwidth | size |
|---|---|---|---|
| SRAM (L1, L2, L3) | 1 - 2 ns | 200 GB/s | 1 - 20 MB |
| DRAM (memory) | 70 ns | 20 GB/s | 1 - 20 GB |
| Flash (disk) | 70 - 90 μs | 200 MB/s | 100 - 1000 GB |
| HDD (disk) | 10 ms | 1-150 MB/s | 500 - 3000 GB |
Cashing
save the most useful memory as near as possible.
Cash hierarchy
hardware management
- L1 instruction / Data cashes
- L2 unified cache
- L3 unified cache
software management
- Main memory
- Disk
Other consideration of memory
Banking
avoid multiple access
Coherency
Memory controller
Increasing Data-level parallelism (DLP)
vector
motivation
for(int i = 0; i < N; i++)
{
A[i] = A[i] + B[i] + c[i];
}when N is very big, need to be faster, because each instruction per loop are independent, change the code into:
for(int i = 0; i < N; i+=4)
{
// working on parallel, 4 "threads"
A[i] = A[i] + B[i] + c[i];
A[i+1] = A[i+1] + B[i+1] + c[i+1];
A[i+2] = A[i+2] + B[i+2] + c[i+2];
A[i+3] = A[i+3] + B[i+3] + c[i+3];
}Single Instruction Multiple Data (SIMD)
- ALU is wide
- register is big
x86 vector sets
SSE2
- 4-width float or integer instruction
- Intel Pentium 4 onwards
- AMD Athlon 64 onwards
AVX
8-width float or integer instruction
Intel Sandy Bridge
AMD Bulldozer
Increasing Thread-level parallelism (TLP)
simultaneous multithreading (SMT)
Including:
instruction streams
private PC ,registers, stack
Shared global, heap
Thread can be created or destroyed.
Both programmer and OS can schedule it.
multicore
Pure replicating the whole pipeline. (Sandy Bridge-E: 6 cores)
- √ full core, don not share other resources except the L1 cache
- √ keep the mole's theory
- × problems of multicore thread of efficiency
Locks, Coherence and Consistency
multiple threads read-write same data -- add lock
who's data is correct -- coherence
which type of data is correct -- consistency