Masked Autoencoder(MAE)
Published in Dec 2021, this new work by Kaiming He draws a lot of attention from the community. The astounding result of unsupervised transfer learning and the capability of reconstructing highly masked (up to 90%) images might herald a new era in CV.
This is a series of paper reading notes, hopefully, to push me to read paper casually and to leave some record of what I've learned.
Paper: Masked autoencoders are scalable vision learners
Useful link: https://www.bilibili.com/video/BV1sq4y1q77t/
| NLP | CV | |
|---|---|---|
| Supervised | Transformer[17] | ViT[8] |
| Self-supervised | Bert[1] | MAE |
Inspired by Bert[1] and ViT[8], MAE shows the capability of unsupervised learning on CV. It's not the first work to expand Bert [1] to CV, but it might be the most influential one. It might accelerate the application of transformer in CV, as Bert[1] has done with NLP.
Notes
Title
Note the title format, "Something is a good fellow", is same as the GPT[2] series. It is a powerful format to include the distilled conclusion in the title.
Abstract
This paper proposes an asymmetric, transformer-based, denoising auto-encoder architecture. The unsupervised pre-training task is to reconstruct highly masked input images. The high masking ratio is the key. It reduces the pre-training time by 3 times and is able to train larger model efficiently, resulting in competitive reconstructing accuracy. The transfer performance is even better than the supervised pre-training models.
Key figures
First, the reconstruction results are shown below.


Although the details are vague, the reconstruction of the main content is astonishing. Note that maybe not all of the validation images turned out as good as this, but this result is still really surprising.
Conclusion
The model is said to be simple(false) and scaled well(as long as you are rich). The results show that MAE makes scaleable unsupervised pre-training in CV applicable, a similar route to that of NLP[1][2].
Besides, they claim the semantic difference between text and image leads to different masking operations. Furthermore, they mention that the patch masking operation does not separate semantic entities, meaning one masked patch may include more than one piece of semantic information, unlike language. As a result the reconstruction results show that the model manages to learn from complex semantics.
Introduction
Although yielding excellent success in NLP, applying scalable unsupervised models in CV is still a challenging problem. But why? i.e. what makes masked autoencoding different between vision and language? 3 reasons are discussed:
The architecture difference between convolution and transformer: it's hard to integrate masked embedding or positional embedding to the convolution layer (Actually positional embedding is not needed for convolutional layer) -- addressed by ViT[8].
The information density difference between text and image: Unlike high-semantic text, natural signals in images possess heavy spatial redundancy -- addressed by masking a very high portion of random patches.
Decoder difference: in NLP, take BERT as an example, a simple linear projection is used as a decoder, while in vision, a simple decoder is not powerful enough to reconstruct the semantic level information -- addressed by substituting linear projection with transformer layers.
Then, the idea of MAE is on the front door. The encoder processes only the unmasked patches, while the lightweight decoder reconstructs the whole image from the encoded latent representation and the [mask] tokens. With a very high masking ratio(e.g. 75%), the pre-training time can be reduced by 3 times.
Besides, the data capacity and generalisation performance are great. SOTA accuracy is achieved with fine tuning on a medium-sized dataset (ViT-Huge model on ImageNet 1K).
In this section, the reason why designing such an architecture is well presented through Q&A, highly recommended. Sometimes, motive is an important factor in distinguishing a paper from a technical report.
Relate work
Works in 4 areas are briefly reviewed.
Note that BEiT[9] is very similar to MAE, while BEiT[9] projects each patch to a label and predict as Bert[1], unlike projecting to pixels in MAE. Besides, the recently popular constructive methods [14][15][16] relay on data augmentation heavily, while MAE does not.
Approach
The architecture and the training approach is briefly covered in the sketch below:
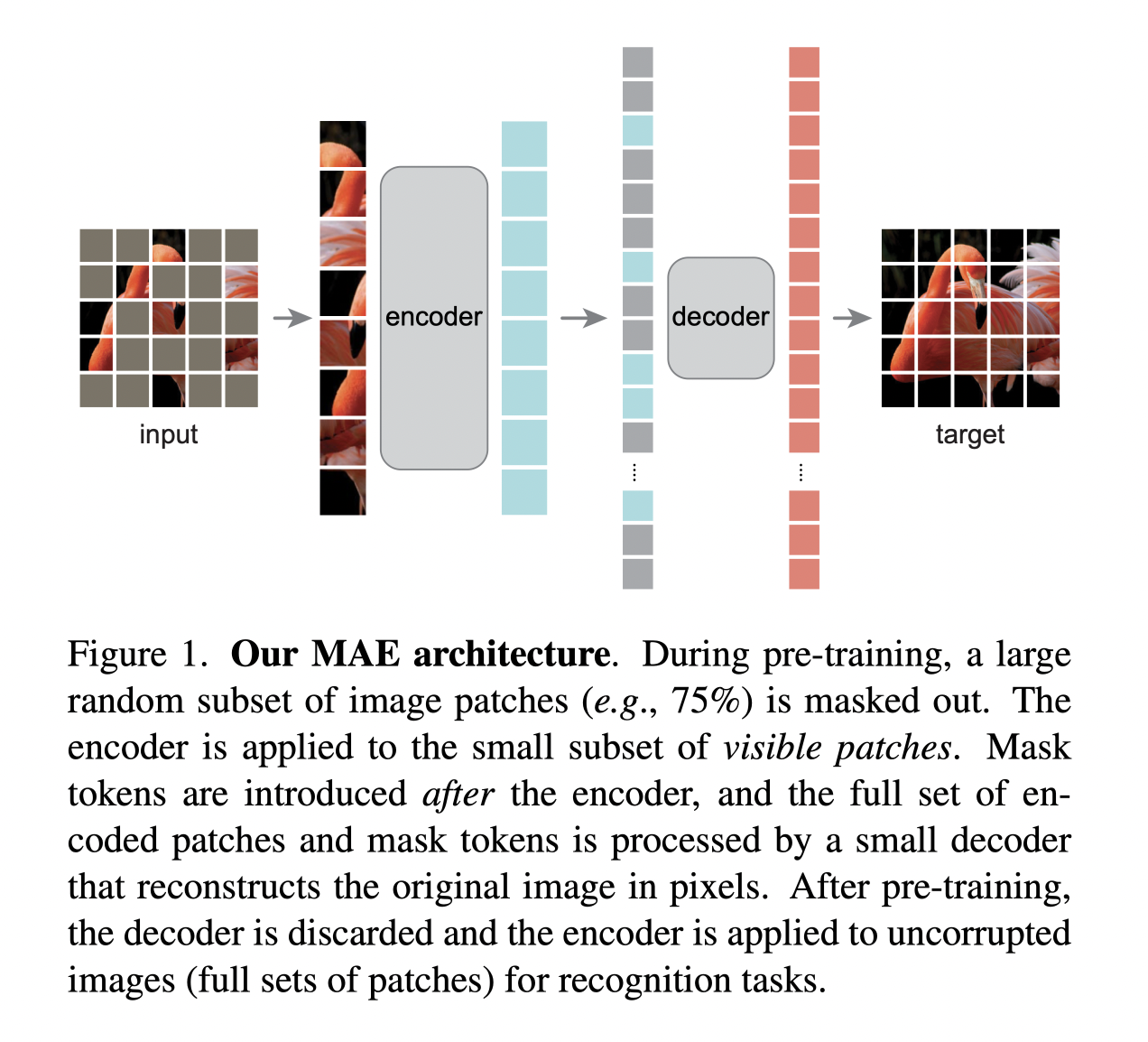
Additional details about the architecture: For per-processing, non-overlapped patching and random uniform masking are adopted. The [mask] token is shared, and another position embedding is introduced to the decoder input so that the inputs are different on different masked area. But it is unclear whether the positional embedding is performed only on the [mask] token or on the whole input, i.e. encoded patches + [mask] token. Furthermore, the lightweight decoder has <10% computation per token compared with the encoder.
Reconstruction target: The decoder aims to recreate the pixels of masked patches. The loss function is the mean squared error (MSE) between the output and the original image, only on the masked region of course. Besides, a variation reconstructing the normalised pixels shows an improvement in representation quality.
Implementation: The random masking step is applied by shuffling and dropping the last part. And un-shuffling is used before the decoder to reconstruct the position. In this way, no sparse operation is needed and the cost becomes really low.
ImageNet experiments
Setup
The model is self-supervised pre-trained on the ImageNet-1K, then evaluated by 2 kinds of supervised training: (i) end-to-end fine-tuning and (ii) linear probing(only the last linear projection layer is allowed to update). ViT-Large (ViT-L/16)[8] is used as baseline backbone.
Note that they reproduce the full supervised experiments by ViT[8] and get 8% higher accuracy. The trick is a strong regularisation(75%). May be it meets the previous theory of the semantic difference between picture and text.
| Supervised, original[8] | Supervised, their impl. | Self-supervised, Baseline |
|---|---|---|
| 76.5 | 82.5 | 84.9 |
Ablation
Most of the result are recoded clearly on the figures and tables below,
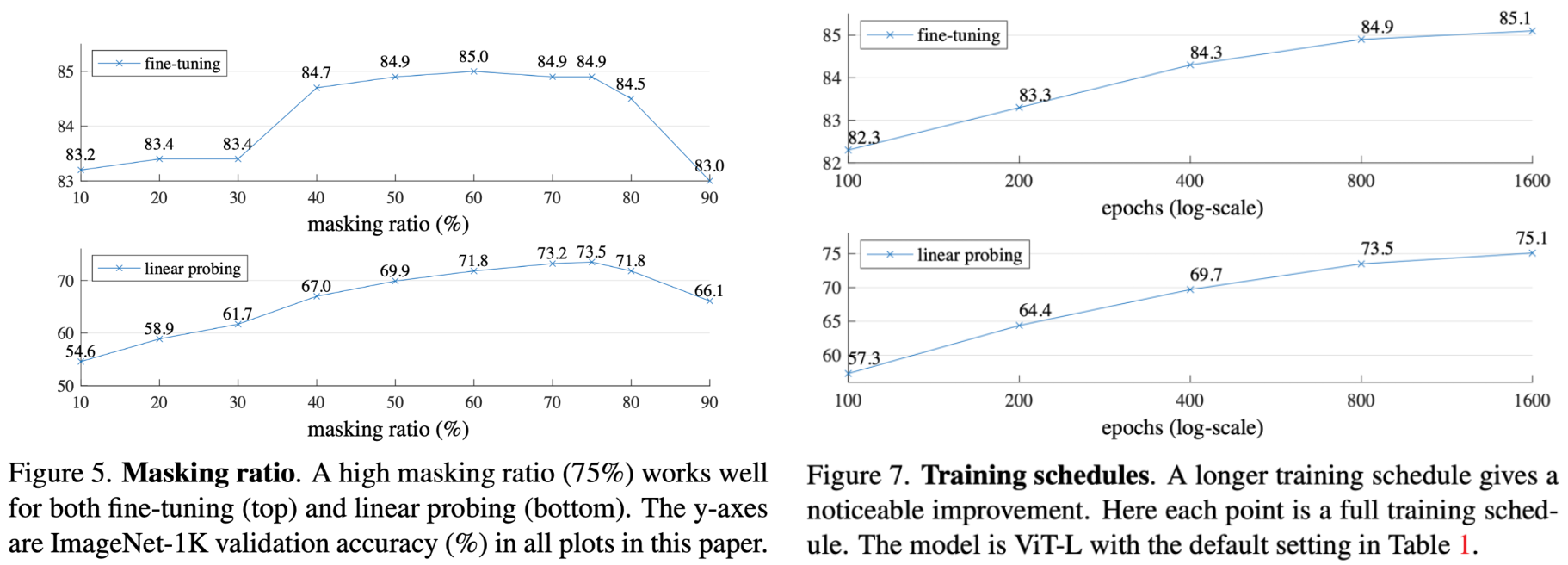

Just add some details:
- Best mask ratio is higher than BERT[1] (15%) and iGPT[7], ViT[8]and BEiT[9] (25%-50%)
- The encoder manages to learn the semantic representations given that the semantic pieces are mixed in each input patches, different from NLP
- No saturation of linear probing accuracy is observed, indicating the overfitting is not severer even at epoch 1600
- One explanation for (a): a reasonably deep decoder can account for the reconstruction specialisation, leaving the encoder to extract a more abstract latent representation.
- One explanation for (c): current architecture only process known patches, the introducing of unknown [mask] token would result in a gap between the pre-train task and inference task.
- Result of (d) indicates that high-frequency components are useful in MAE. And the dVAE token case is actually what BEiT[9] does, projecting each patch to a single token.
- Result of (e) distinguishes MAE from contrastive learning and related methods. In MAE, the random masking plays the main role of data augmentation.
Comparison
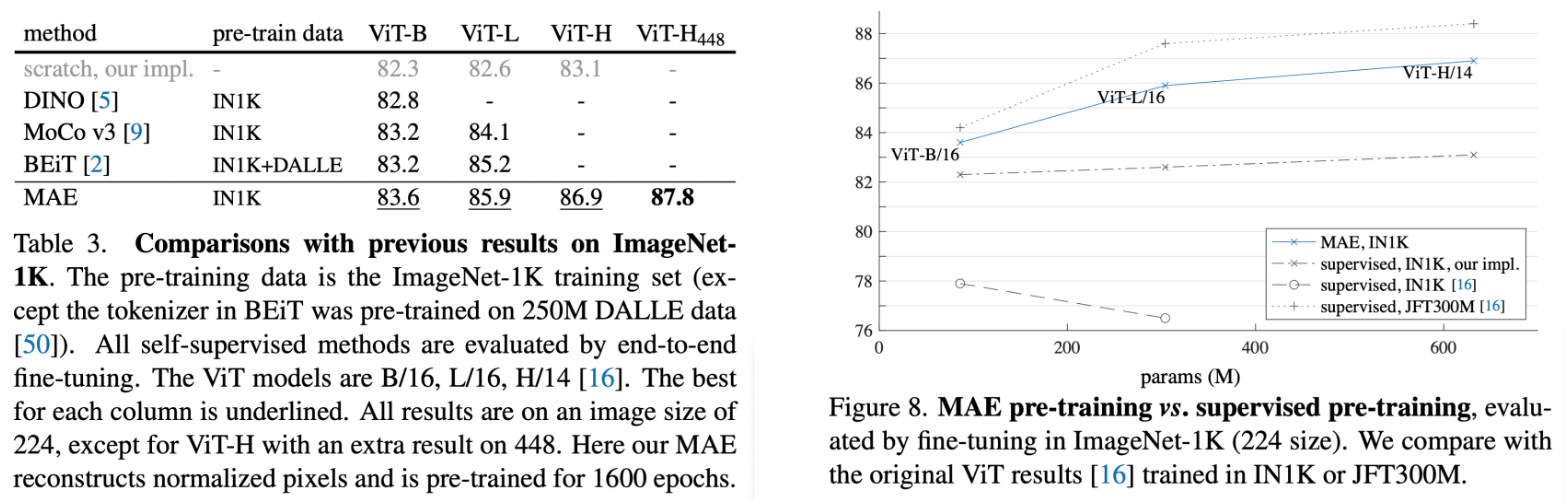
- with unsupervised models: not only the accuracy is better, the pre-training time is shorter than the competitors as well
- with supervised models: it indicates that MAE can help scale up model sizes. And the MAE performance on ImageNet1K is similar to the model trained on the 300 times bigger dataset JFT300M. But, considering the number of class of JFT300M is much more than ImageNet1K as well, the result is slightly unfair.
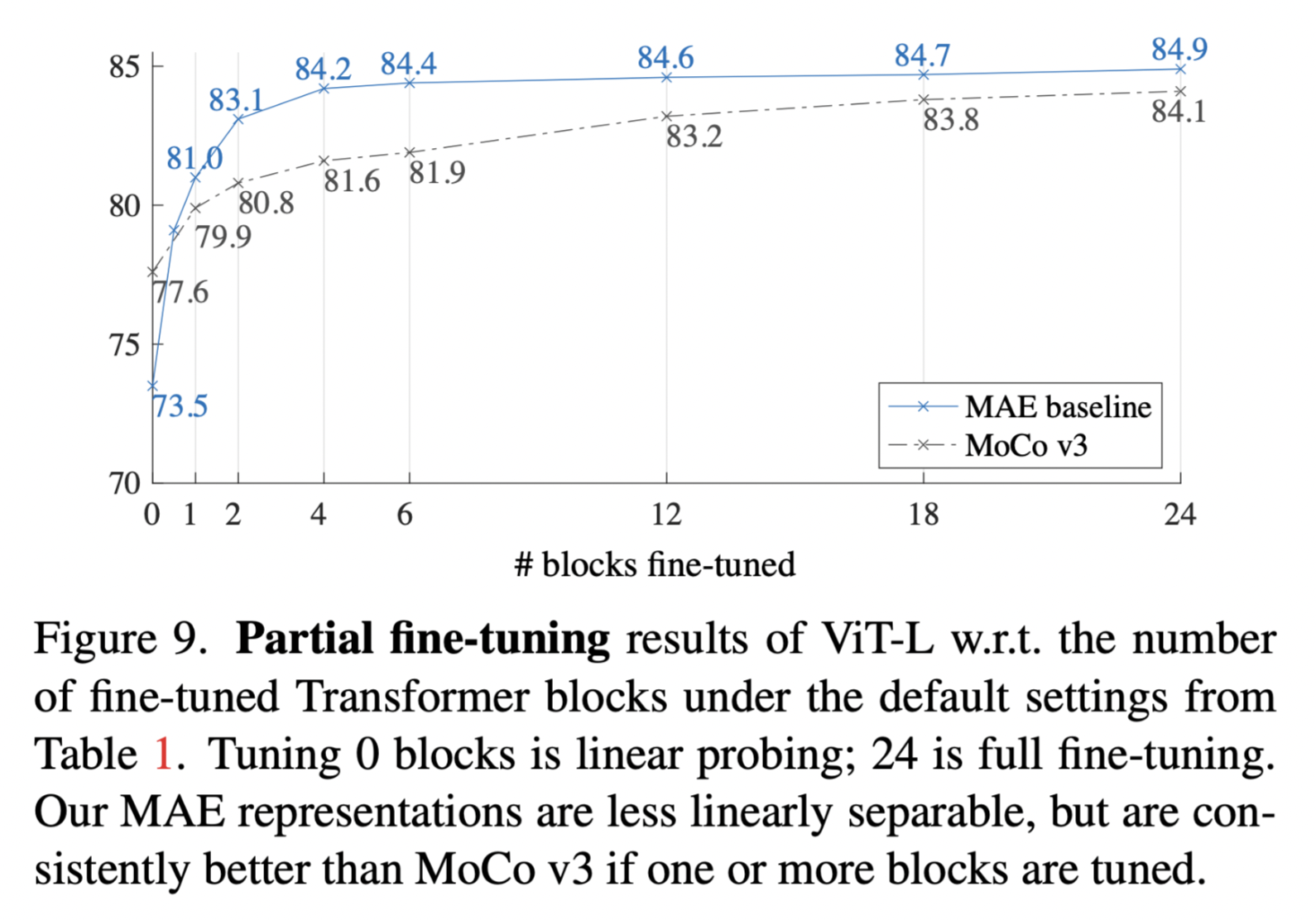
Partial Fine-tuning
In addition to the full fine-tuning and 0 fine-tuning (linear probing), partial ones are applied by fine tuning fixing several layers. The result indicating at least the last 6 layers are task-related.
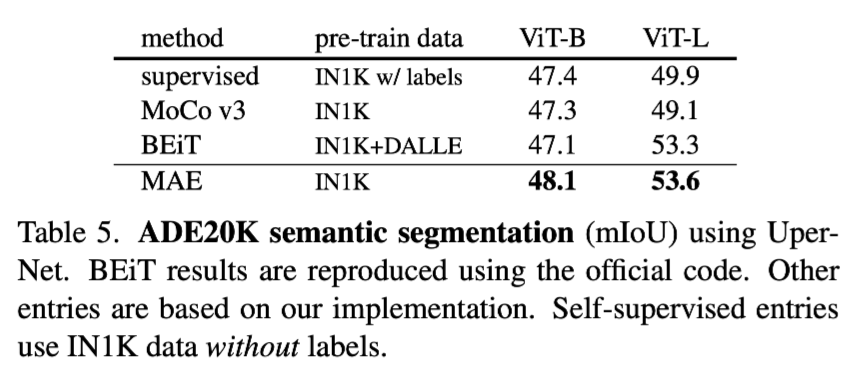
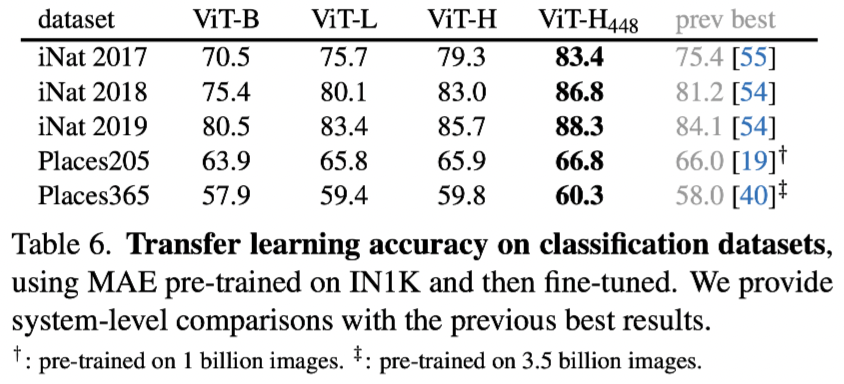
Transfer learning experiments
At last, down steam tasks are evaluated compared with other frameworks.
![]()
Review
Writing, simple but has a very good storyline. From the full introduction of the motivation, to the detailed clear figures explaining each part of the design.
The algorithm is simple, just applying self-supervised learning to CV based on ViT[8]. 2 key points are introduced:
- More patches need to be masked
- Transformer decoder to reproduce the pixels instead of a simple linear layer projecting patches into tokens.
In conclusion, a simple idea, a great result and detailed experiments make this paper a great work.
Reference
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. ↩︎
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. ↩︎
- Hinton, G. E., & Zemel, R. (1993). Autoencoders, minimum description length and Helmholtz free energy. Advances in neural information processing systems, 6. ↩︎
- Vincent, P., Larochelle, H., Bengio, Y., & Manzagol, P. A. (2008, July). Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning (pp. 1096-1103). ↩︎
- Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., Manzagol, P. A., & Bottou, L. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of machine learning research, 11(12). ↩︎
- Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. (2016). Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2536-2544). ↩︎
- Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., & Sutskever, I. (2020, November). Generative pretraining from pixels. In International Conference on Machine Learning (pp. 1691-1703). PMLR. ↩︎
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. ↩︎
- Bao, H., Dong, L., & Wei, F. (2021). Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254. ↩︎
- Wang, X., & Gupta, A. (2015). Unsupervised learning of visual representations using videos. In Proceedings of the IEEE international conference on computer vision (pp. 2794-2802). ↩︎
- Noroozi, M., & Favaro, P. (2016, October). Unsupervised learning of visual representations by solving jigsaw puzzles. In European conference on computer vision (pp. 69-84). Springer, Cham. ↩︎
- Zhang, R., Isola, P., & Efros, A. A. (2016, October). Colorful image colorization. In European conference on computer vision (pp. 649-666). Springer, Cham. ↩︎
- Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728. ↩︎
- Wu, Z., Xiong, Y., Yu, S. X., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3733-3742). ↩︎
- Oord, A. V. D., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748. ↩︎
- He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738). ↩︎
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30. ↩︎