Vision Transformer
Presented in 2021, the vision transformer model (ViT) is the most influential work in the CV field recent years. Its variants outperform the dominant convolutional networks in almost all CV tasks such as classification and object detection. And it breaks the border of CV and NLP, providing new thoughts to CV and multi-model areas.
This is a series of paper reading notes, hopefully, to push me to read paper casually and to leave some record of what I've learned.
Paper:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Useful links:
https://www.bilibili.com/video/BV15P4y137jb
https://theaisummer.com/vision-transformer/

Not only Vision Transformer (ViT) performs better on traditional CV tasks, it has more impressive properties. As shown above, Naseer et al. demonstrate the tasks where ViT shows extra performance over CNN models, even over humans.
Notes
Abstract
While Transformer-based models such as BERT, GPT series, and T5 nail the NLP tasks, CV tasks remain dominated by CNN-based models. This paper applied a pure transformer encoder (same as BERT) to sequences of cut images and obtains a good classification result, especially with supervised pre-training on a large dataset then fine tuning on a mid-size dataset. Besides, fewer computational resources (meaning 2500 days of TPUv3) are need to attain good results, compared with CNN models.
Conclusion
Besides the paraphrasing part, the conclusion part discusses the future work based on the ViT. And all of them have follow-up works.
- Apply ViT to other CV tasks, given the promising performance of DETR. Only 1 and a half month later, ViT-FRCNN and SEDR mange to apply ViT on detection and segmentation respectively. And after 3 months, Swin Transformer introduces hierarchical feature to transformer, making ViT more suitable to vision tasks.
- Self-supervised pre-training, given the great results of BERT and GPT in the NLP field. Initial explorations in the paper show a gap from the supervised pre-training. One year later, MAE narrows the gap successfully by generative model.
- Further scaling up this model. Half year later, same group introduces Vit-G with two billion parameters, attaining new SOTA on ImageNet of 90.45%.
Introduction
Success of Transformer-based models on NLP tasks are firstly reviewed. And it is natural trying to apply such self-attention mechanism to vision. Yet here are one major obstacle:
- How to transfer a 2D picture to a 1D sequence?
One intuitive thought is to flatten the picture directly and treat each pixel as an element. In this way, a medium size 224*224 picture will be converted to a 50,176 long sequence. However, the sequence length is quadratically related to model complexity. Morden hardware only supports input sequence length <1000 of a pure self-attention model. For example BERT only accepts input length of 512.
Yet the authors mange to incorporate the original transformer encoder in CV. In order to address the sequence length problem, they split the image into 16*16 patches, each patches denotes a sequence element (token). In this way, a 224*224 image can be converted as a sequence length of 16*16 with each element sized 14*14. Each element then gets linearised through a FC layer before being passed into the transformer encoder.
And the afterwards experiments show that the new model doesn't perform well on mid-size model. One explanation is that transformer model lack the image-related inductive bias of CNN (locality and translation equalisation). Yet with pre-training on large dataset such as JFT-300 and ImagNet-21K, a better result than CNN can be approached.
Related work
It is a detailed related work covering all the aspects in the original paper. I just pick few of them.
All the related works aim at reducing the sequence length within the limitation caused by self-attention. Some try to combine CNN with self-attention. For example Wang, X et al.'s work takes the feature map extracted by CNN as the input of transformer. Others try to replace the CNN with a special variation of self-attention. For example, Ramachandran et al.'s work replaces all convolutional sublayers of the ResNet-50 model with self-attention layers. To reduce the computational cost, a local region of the image instead of the whole image is used as the receptive field of the self-attention layer, meaning each pixel only attends to its neighbours in a restricted area. In another work line, Wang, H et.al's work factorising 2D self-attention into two 1D self-attentions to significantly reduce computation complexity.
And there is a very similar Cordonnier et al's work also split the images before the self-attention layer. Yet the patch size is 2*2 and with the dataset only CIFAR-10. This paper enlarges the model, apply it in big dataset, and shows the scalability.
Another related work image GPT(iGPT) trains a GPT-2 scale generative network. Yet the highest accuracy on ImageNet is 72%, way less than 88% of this paper. But in 2021, an afterwards generative network MAE shows a competitive result of 87.8%, with good transfer leaning capability on segmentation and object detection as well.
Besides, works exploring transfer learning performance of CNN model on larger datasets such as ImageNet-21k and JFT-300M are mentioned. And this paper studies the transformer instead of the CNN.
Method
The whole big idea of the method part is leaving as much as possible the original transformer architecture in order to leverage the good feature and the existing mature efficient implementations of it.
Vision Transformer (VIT)
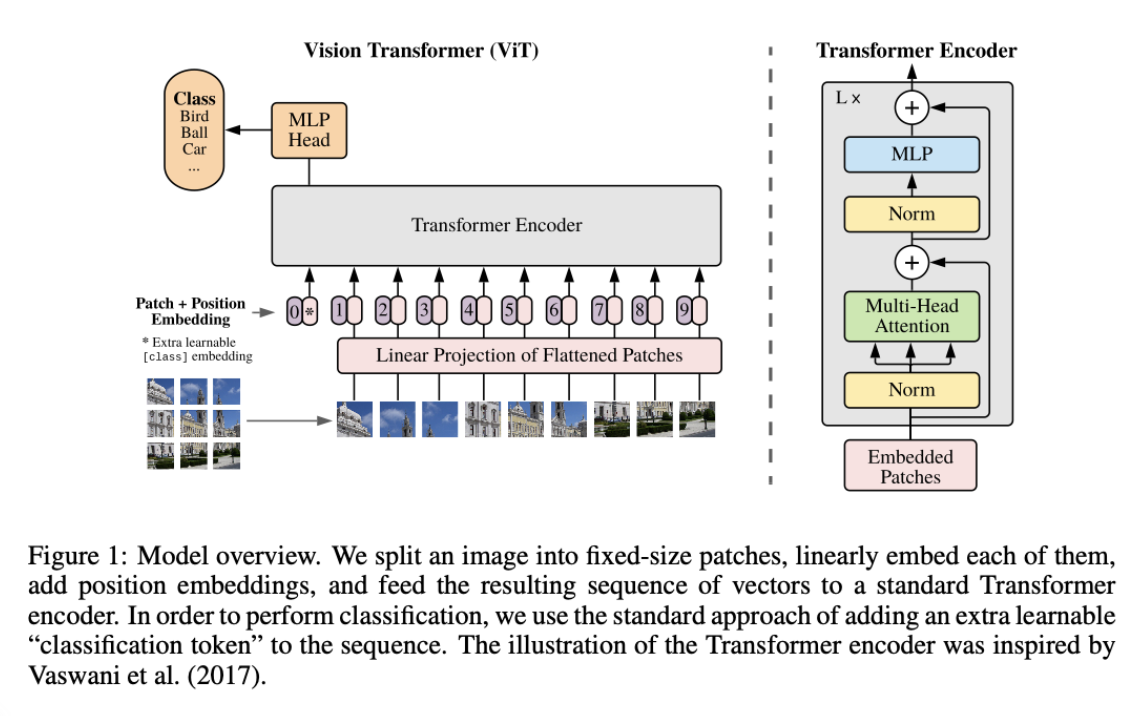
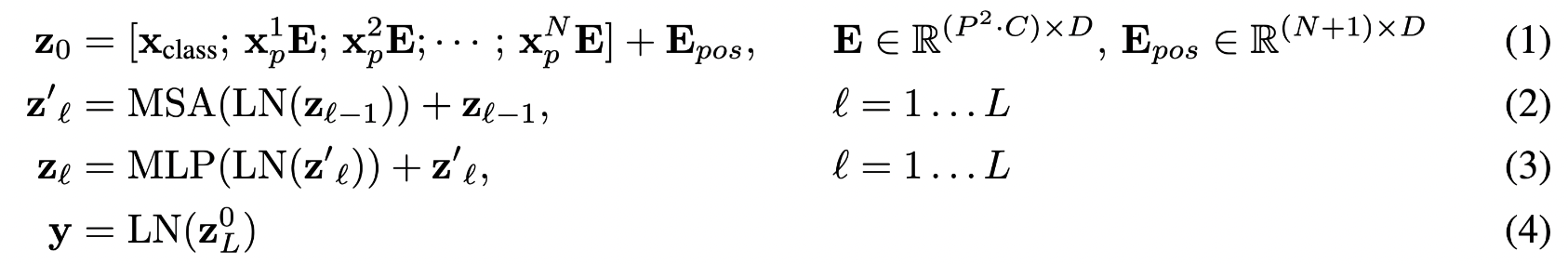
From the overview, and the algorithm it should be called Vision BERT instead of Vision Transformer, given the pure encoder architecture and the extra "classification token". Assume a 224*224*3 image, after patching, the sequence length is HW/P2=16*16=196 and the width is 14*14*3=768. Given the hidden size of the model D=768, through linear projection layer (E), sequence X [196*768] are multiplied with weight E [768*768]. The resulting linear output [196*768] is then contacted with [cls], followed by adding standard 1D learnable positional embedding to be the transformer input [197*768]. After several transformer blocks, the output size does not change and the [cls] token is projected to a softmax classification layer
Ablation experiments
The pre and post-processing are crucial for ViT given that the middle transformer encoder layers are kept as original. Multiple rounds of ablation experiments are carried out.
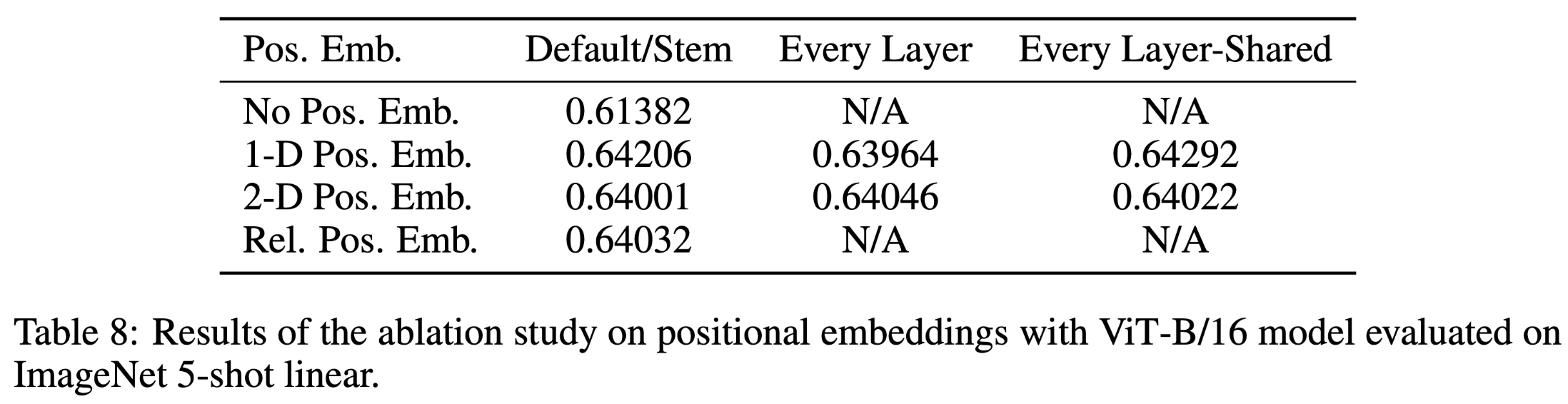
Position embedding schemes, 2D embedding and relative embedding are applied to compare with the standard 1D embedding, and no evident gain is spotted.
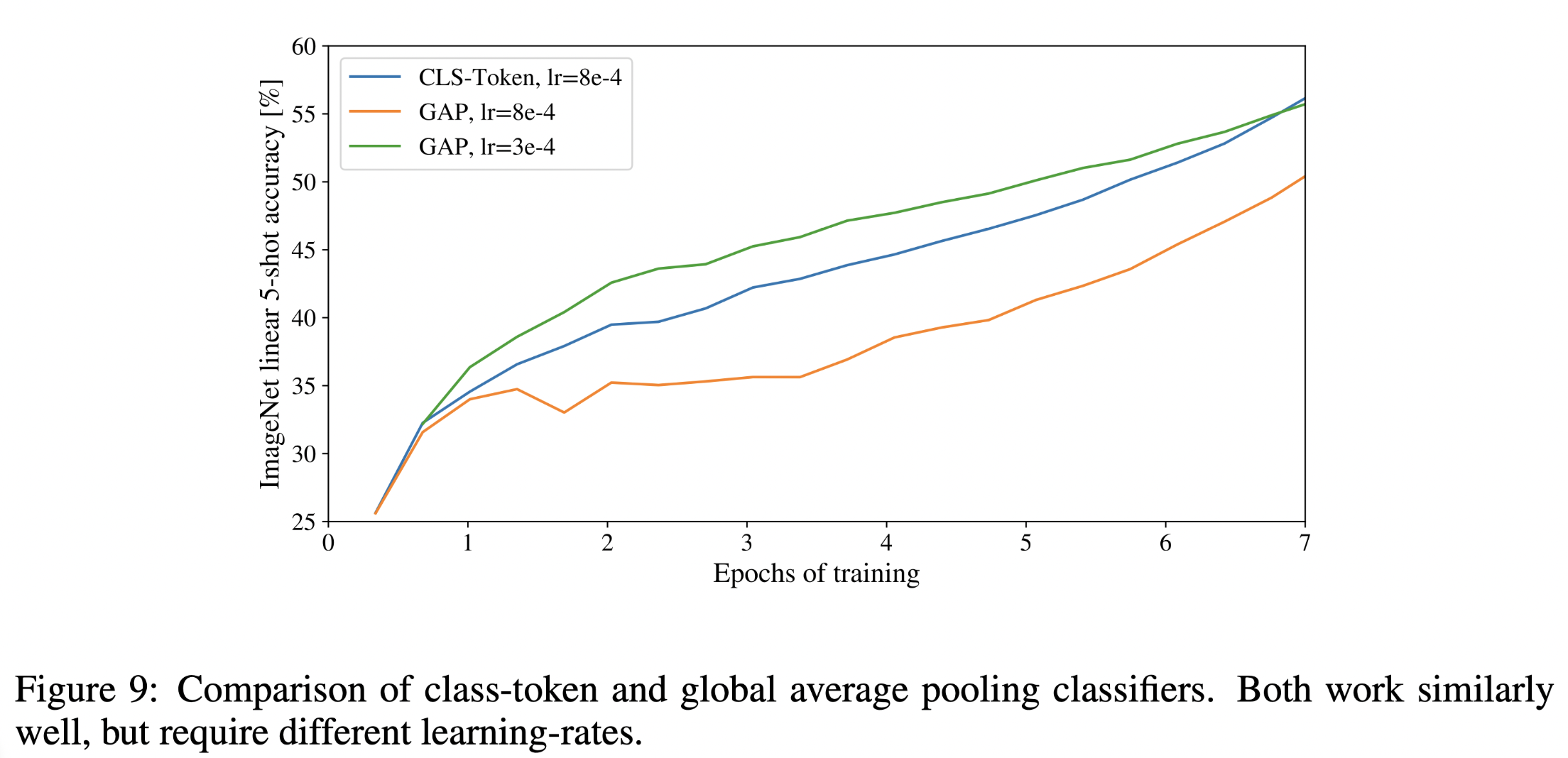
[cls] token vs average pooling, extra [cls] token is inherited from the Transformer model for text, and traditionally in CV, instead of an additional token, an average polling layer after the output layer is usually used as a classifier. The figure blow shows no both works. But in order to stick the original design as close as possible, [cls] token is applied.
Another analysis after the model description:
Inductive bias: Less locality, translation equivariance and 2D neighbourhood structure are possessed by ViT, compared with CNN.
Hybrid Architecture: CNN can be used as a special embedding, leveraging the inductive bias of the CNN model.
Limitation on Fine-Tuning
Pre-train ViT at larger and higher resolution datasets is proved to be beneficial. Yet the input sequence lengths are different when training on two datasets with different resolutions, resulting in positional embeddings of different lengths. In this article, a 2D interpolation is applied to transfer a pre-trained positional embedding to another dataset to fine-tune. But the accuracy will loss if the resolution difference is too big.
Experiments
Setup
ResNet, ViT, and the hybrid model are evaluated together and ViT wins taking account of the pre-training cost. Besides, a small self-supervision experiment is deployed and sees potential.
Two scales of ImageNet(1k and 21k) and JFT(303M) are used as pre-training dataset. Only classification tasks are evaluated with popular datasets.
3 scales of ViT are designed with different patch size(inversely proportional to the amount of data). For example, ViT-L/16 means ViT-Large with 16 patches.
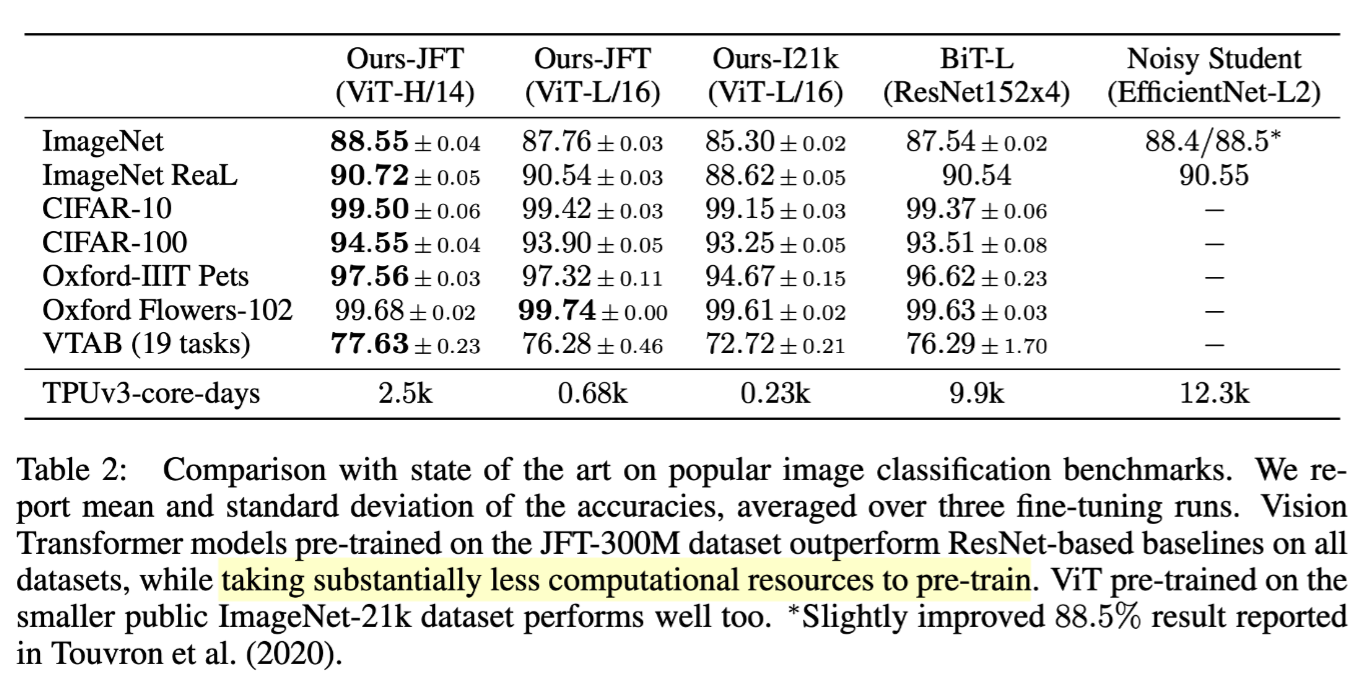
Comparison to SOTA
And the best results are shown below:
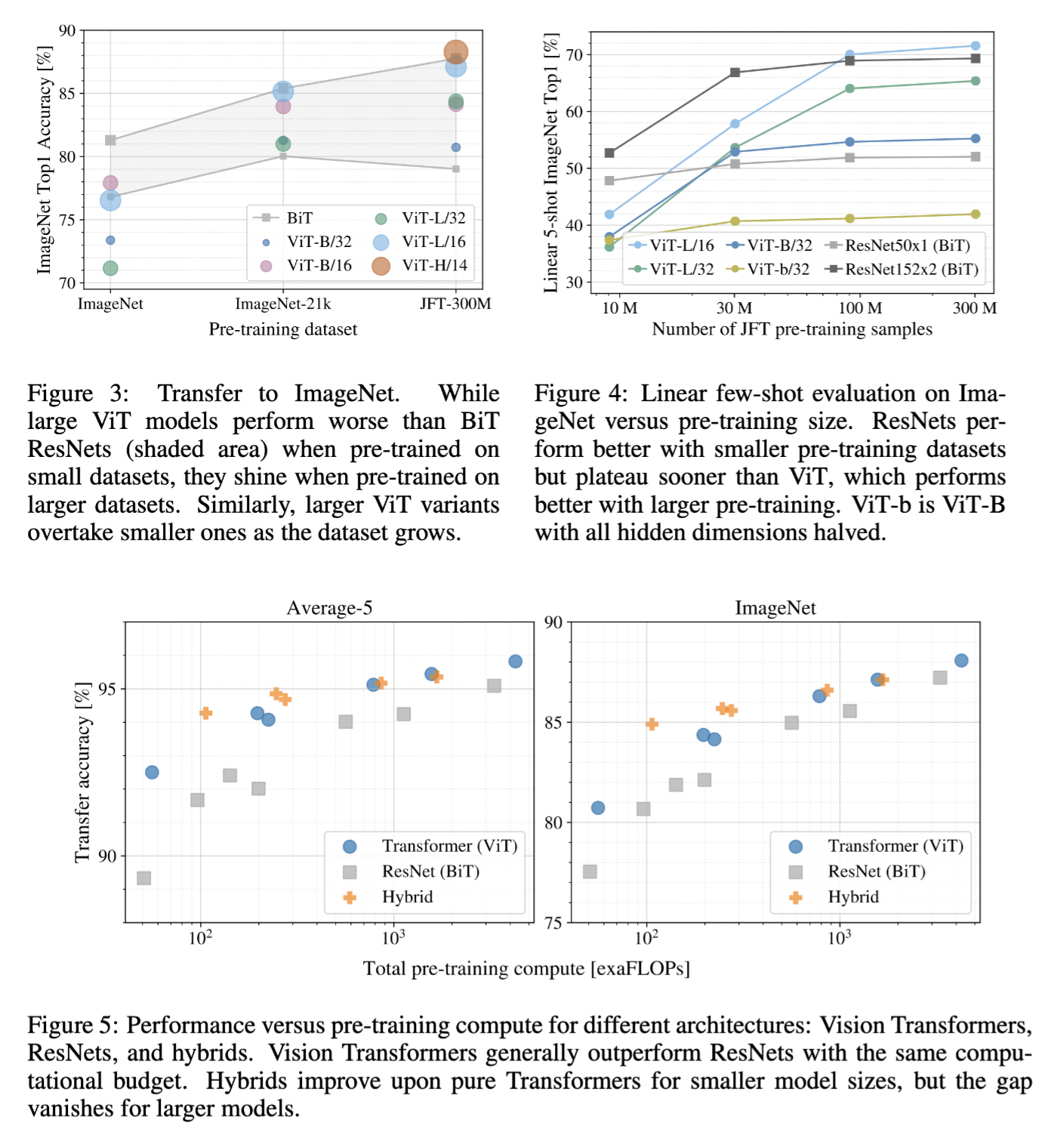
Pre-training cost requirements
Figure 3 and 4 shows the performance of the presented models on different sizes of per-training datasets. ViT preforms competitive only starts from dataset 21k, and very well only on huge dataset.
Figure 5 shows the transfer performances versus pre-training costs on JFT-300M of several models. And it shows that ViT is cheaper than ResNet. Interestingly, the Hybrid model is competitive on low pre-training cost.
Inspecting ViT

Figure7 Left: The learned linear projection weight matrix E [768*768] is inspected by PCA, and the first 28 components(modes) are visualised as embedding filters. They look pretty much similar to the early layer filters(kernels) of CNN (for example, the first layer of a CNN shown by Brachnmann et.al). This similarity indicates that the linear patch embedding manages to represent the low-dimension structure of each patch. 
Figure7 mid: Position embedding visualisation first shows that the spatial information is captured well by the E matrix, given that the similarity matrix between patches matches well with the distance relationships of patches. Second, patterns across rows (and columns) have similar representations, indicating the embedding layer has successful learned the row-column relationship. Overall, the 1D positional embedding has learned the 2D structure, coherent with the ablation experiment result.
Figure7 Right: The receptive fields of the multi-head attention layers are evaluated by the mean attention distance. Compared with CNN whose receptive field increases linearly with the depth, the ViT attends the whole picture from the first layer, leveraging the natural advantage of transformer.
Self-supervision
A preliminary exploration on masked patch prediction for self-supervision (mimicking one of the BERT pre-training tasks) has been employed. But the result is not satisfying. And contrastive pre-training are mentioned as a future work.
Review
This is a concise-written, fundamental article. Just as presented in the conclusion part, it inspired many flow-up works from any direction in the CV area, such as applying to more tasks, changing the architecture(tokenisation, transformer block(MLP-mixer: changing multi-head attention layers to MLP , meta-former: substituting multi-head attention layers to average pooling), changing objective function(self-supervised, contrastive learning), and multi modality.
It's still unclear whether convolution, attention or MLP will win this game.