GPT1-3
GPT-3 is the most popular generative language model now. With more than 100 billion parameters, the performance is proved to be great and by now there are more than hundreds of works (commercial or academic) built on it, including the famous GitHub Copilot.
This is a series of paper reading notes hopefully, to push me to read paper casually and to leave some record of what I've learned.
Paper links:
GPT-1: Improving language understanding by generative pre-training
GPT-2: Language models are unsupervised multitask learners
GPT-3: Language models are few-shot learners
Useful links:
https://www.bilibili.com/video/BV1AF411b7xQ/
GPT-3 Demo: 300+ GPT-3 Examples, Demos, Apps
GPT-3: Demos, Use-cases, Implications
Since my own interest is not NLP, I haven't read these paper by myself. Instead, I follow a reference video above directly and make notes together with it.
History and Timeline
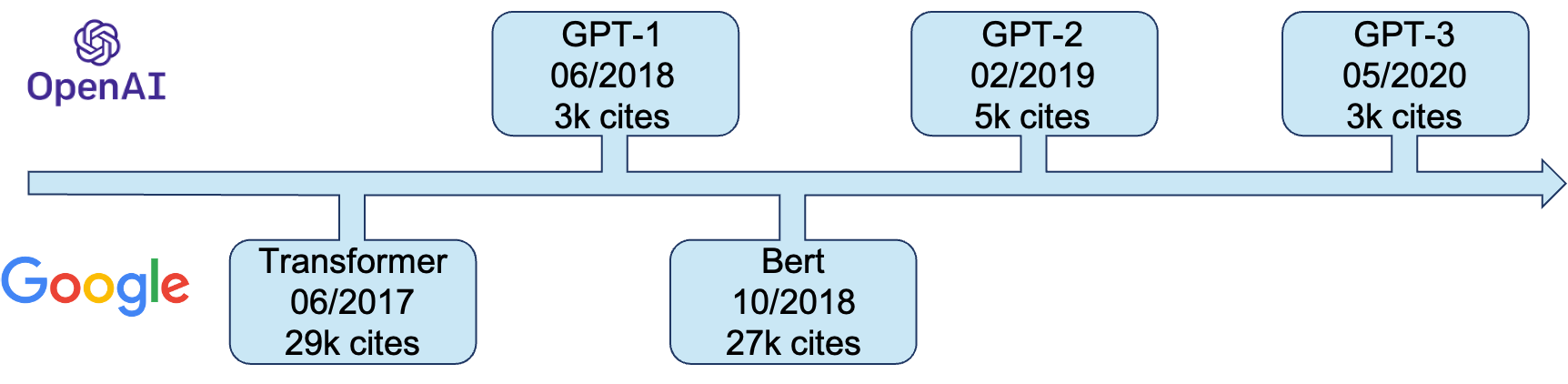
Given that the GPT series are all developed by the OpenAI and the Transformer & Bert are developed by Google, it seems there are two companies combating. And it is inevitable to compare these two series.
From the perspective of number of cites, it is obviously that OpenAI have catch less attention from the academic world despite the huge cost. But it's not because GPT series are less novel, but because the goal of GPT series is bigger than that of Transformer & Bert. Transformer is originally developed for Machine Translation task only. And Bert simply aims to push the pre-training technic forward. That's the reason why Bert performs better than GPT if the number of parameters are the same. As a result, GPT is harder and more expensive to train a decent model. And the size of model make others hardly to reconstruct it. From the companies' perspective, OpenAI does this because they want to build the strong AI, but Transformer & Bert are developed only by the teams of Google.
GPT-1
Abstract
The whole idea is similar to what CV did in the last several decades, that is pre-training of a model on a massive dataset followed by fine-tuning on a small specialist dataset. Lacking of large labelled data such as ImageNet of 10 million, however, NLP can't do what CV does exactly. The scale of machine translation database might reach 10 million but one piece of image possesses almost 10 times of information than a sentence. So the database is still not big enough.
GPT makes a big step by using unlabelled data for pre-training. And then aero shot on GPT-2 makes another big step. It is fair to say CV led the trend of deep learning in the first 5 years, but recent years, more new thoughts are coming from the NLP field. And these new thoughts have inspired the CV field as well such as ViT, CLIP and MAE.
Besides, actually it had been a long time since NLP started to use unsupervised pre-training back then. For example, the word embedding model had been used for decades. But, the word embedding can only be seen as a layer, extra layers of model need to be designed to suit for various tasks. With GPT, however, the architecture doesn't need much change, only adjusting the input to suit the tasks is ok.
The result is good but not as good as BERT, but the novelty of this paper is much better than BERT.
Introduction
After briefly introducing the word embedding, problems of pre-training more than word-level data are presented. For example the type of optimisation objectives and how to transfer the extracted information to the tasks. The main reason of this problem is the variety of NLP tasks. There is no way to suit all the needs together.
Then this paper introduces a semi-supervised method which has been explained many times. But actually GPT and BERT are normally called self-supervised model. Though they are the same to me. Semi-supervised learning is a common concept in the Machine Learning. It refers learning from a mix of massive unlabelled data and a few labelled data.
Then the architecture is described. Interestingly, in order to list the reason of choosing transformer over RNN as backbone. The authors say
This model choice provides us with a more structured memory for handling long-term dependencies in text, compared to alternatives like recurrent networks, resulting in robust transfer performance across diverse tasks.
Besides, the paper accents the task-specific input adaptions, which is the key of this paper.
Framework
Unsupervised learning
GPT uses a task that giving the data of un-k to un-1 to predict the un. So the likelihood function to be maximised is:
\[ L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) \] Because the predicting task, the mechanism of the mask multi-head attention of transformer decoder matches the likelihood function perfectly. Because in the first layer of the transformer decoder, the data after u{i} are simply masked to be 0.
And the whole pre-training process is like this:
\[ \begin{aligned} h_{0} &=U W_{e}+W_{p} \\ h_{l} &=\operatorname{transformer}\_\operatorname{block}\left(h_{l-1}\right) \forall i \in[1, n] \\ P(u) &=\operatorname{softmax}\left(h_{n} W_{e}^{T}\right) \end{aligned} \] Compared with BERT, the biggest difference is never encoder or decoder, bidirectional or one-way along. The key is the pre-training task they choose, the completion task that Bert use is much easier than GPT's prediction task. Because this is the difference between interpolation and extrapolation. Therefore, BERT outperforms GPT on the same number of parameters. But the potential of the GPT series goes far beyond BERT. As a result, it took OpenAI years to develop such an impressive GPT-3 model. On another side, however, GPT's prediction task leads to a different architecture with BERT. And the decoder architecture makes the GPT model hard to be bidirectional from the start. We'll see how it conquer this.
Supervised fine-tuning
The fine-tuning task follows the standard supervise learning process as follows:
\[ L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right) \] with \[ P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right) \] And the authors find it helpful to optimise the L1 and L2 together as:
\[ L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda * L_{1}(\mathcal{C}) \]
Task-specific input transformations
The last thing to do is how to apply this framework to different tasks. Similar to with BERT, the pre-trained transformer block doesn't have to be changed.
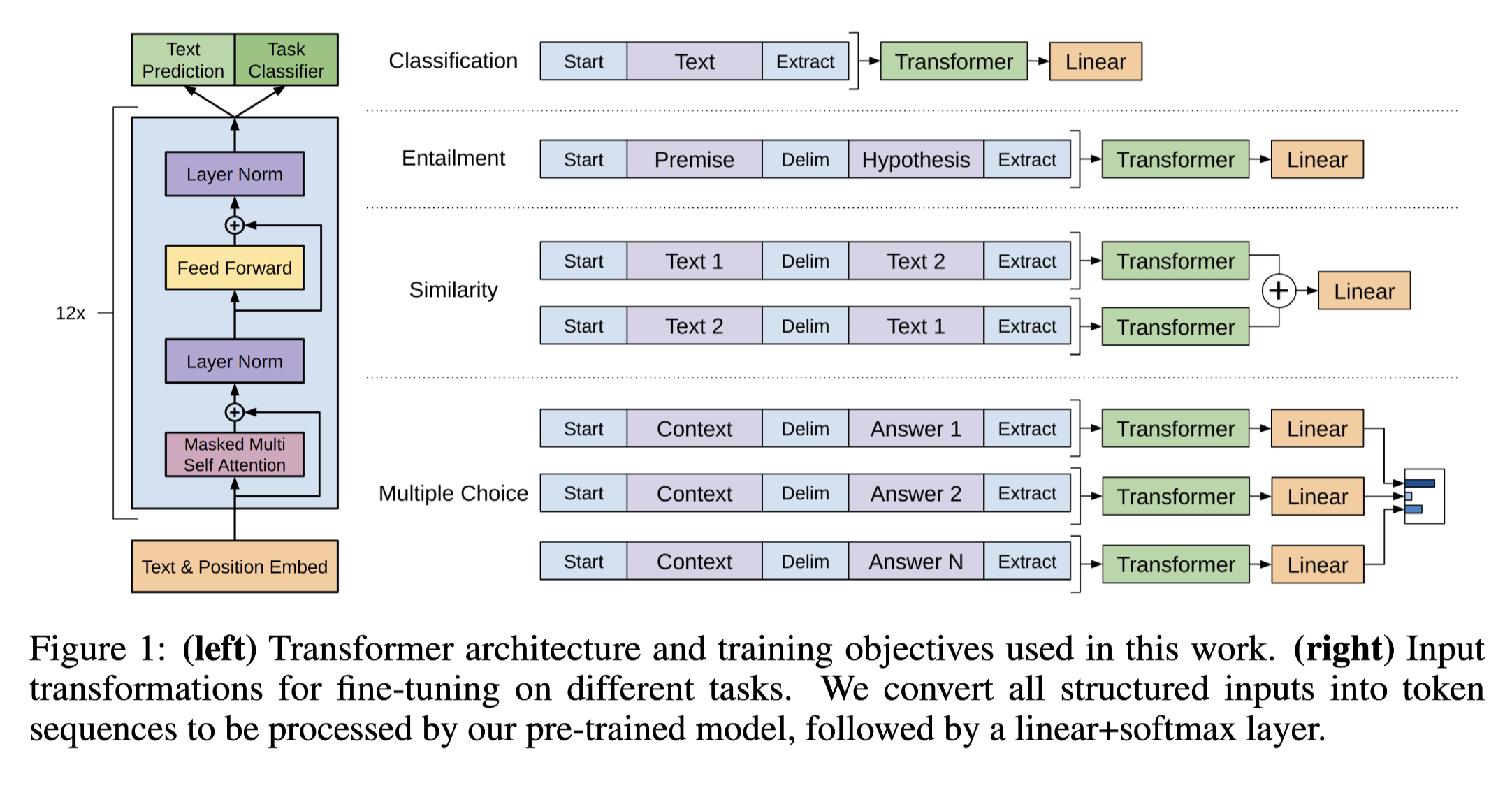
Experiments
The dataset GPT trained on is BooksCorpus dataset, and the model has 12 layers with Hmodel = 768, same as BERTbase. Although the transformer encoder has one layer less than the decoder, GPT and BERT's numbers of parameters are still at the same level. Yet BERT has a 3 times larger BERTlarge model than the base. Because in addition to the BookCorpus dataset, BERT uses one more dataset for pre-training, in total the dataset is 4 times larger than GPT's.
For the pre-training corpus we use the BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words).
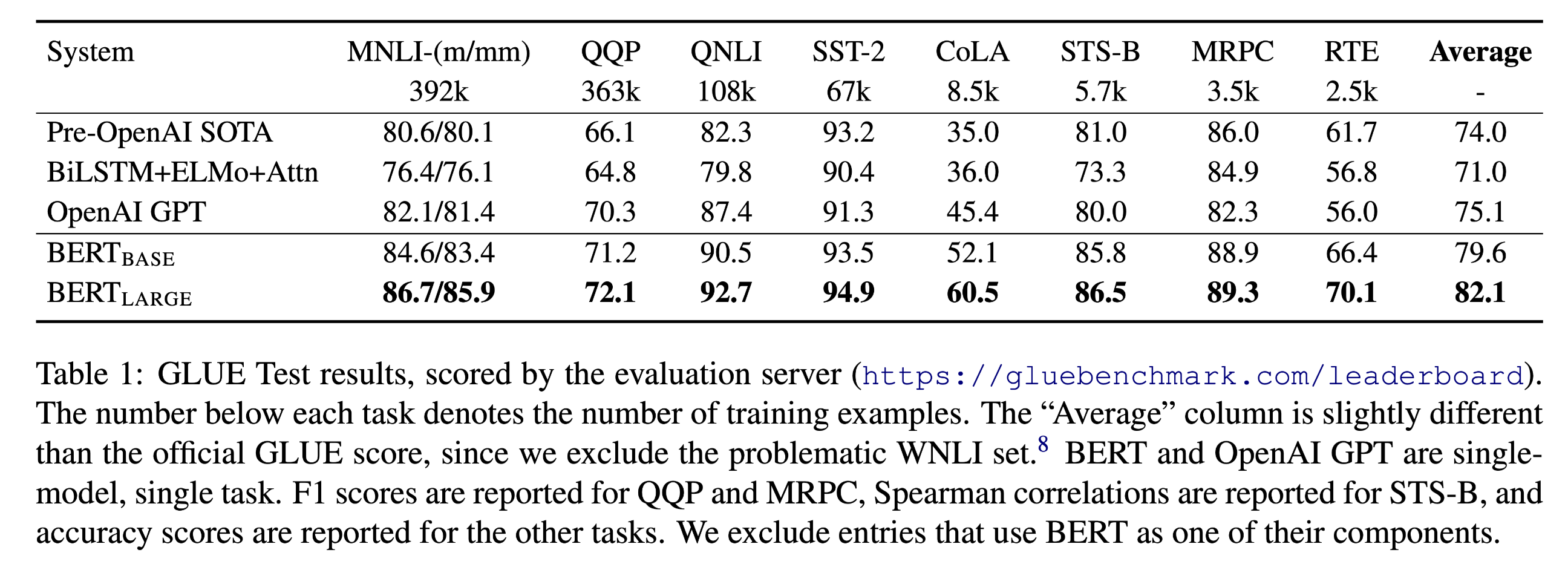
And unfortunately, the average accuracy of BERTbase is higher than GPT at this time. Besides with the BERTlarge model , the accuracy can go higher, as shown below in BERT's paper.
GPT-2
After GPT-1 got defeated by BERT in 4 months, of course, GPT-2 aims to fight back and beat BERT to the ground. Considering the decoder path can't shift to the encoder with dignity, the simplest way then is to enlarge the model and the dataset. But what if it's still not working?
Abstract
After developing a new dataset of millions of webpages called WebText, and training on a new1.5B parameter model. The result turns out to be no significant difference with BERT. So they bring out another sell point, zero shot.
Actually, the zero-shot behaviour is mentioned in the last section of GPT-1's paper in order to understand more of the unsupervised pre-training mechanism. And in GPT-2, this behaviour is brought front to increase the novelty.
Introduction
Zero-shot learning (ZSL) is a problem setup in machine learning, where at test time, a learner observes samples from classes, which were not observed during training, and needs to predict the class that they belong to. Zero-shot methods generally work by associating observed and non-observed classes through some form of auxiliary information, which encodes observable distinguishing properties of objects.[1]
The main-steam approach is one dataset - one task instead of one dataset - multiple tasks because of the generalisation that state of art models lack. Yet multitask learning (trending 2000-2010) represents the idea of training one model with a combination of multiple datasets and different loss functions. So GPT-2 takes the idea of multitask learning and trains the model with the zero-shot setting, under which the downstream tasks can be handled with no collecting of supervised data or fine-tuning. The result is competitive and promising according to the authors.
Approach
The model architectures of GPT1 and GPT2 are pretty much the same. But the input methods are different.
In detail, recalling that during fine tuning process, the GPT1 introduces extra tokens such as [start], [Delim] and [Extract] to modify the input. But in GPT2 without the supervised fine-tuning process, these extra tokens would cause confusion. As a result, the downstream task input need to be more likely to the natural language when constructing.
As a result, the authors introduce what we are used to calling it "prompt", here are the examples:
For example, a translation training example can be written as the sequence (translate to french, english text, french text). Likewise, a reading comprehension training example can be written as (answer the question, document, question, answer).
And afterward, 2 ideas for why this would work are discussed. First, if the model is powerful enough, it might be capable of understanding the prompts. Second, in such a big dataset, this kind of data structure exists. Take machine translation as an example, there should be many sentences containing "translate to French", English text, and French text. The authors point out some of them below.
| Examples of machine translation |
|---|
| ”I’m not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I’m not a fool]. In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as, ”Lie lie and something will always remain.” “I hate the word ‘perfume,”’ Burr says. ‘It’s somewhat better in French: ‘parfum.’ If listened carefully at 29:55, a conversation can be heard between two guys in French: “-Comment on fait pour aller de l’autre coté? -Quel autre coté?”, which means “- How do you get to the other side? - What side?”. If this sounds like a bit of a stretch, consider this question in French: As-tu aller au cinéma?, or Did you go to the movies?, which literally translates as Have-you to go to movies/theater? “ Brevet Sans Garantie Du Gouvernement”, translated to English: “Patented without government warranty”. |
Training data
After considering the need for larger data and the disadvantage(noise) of the existing dataset, they developed a new dataset. The data is collected by first crawling 45 million links discussed on Reddit, and then extracting all the contents of these pages. The dataset contains 8 million documents, 40 GB of text.
Experiment
With 4 level of model, the one-short performances on 4 downstream tasks are shown blow:
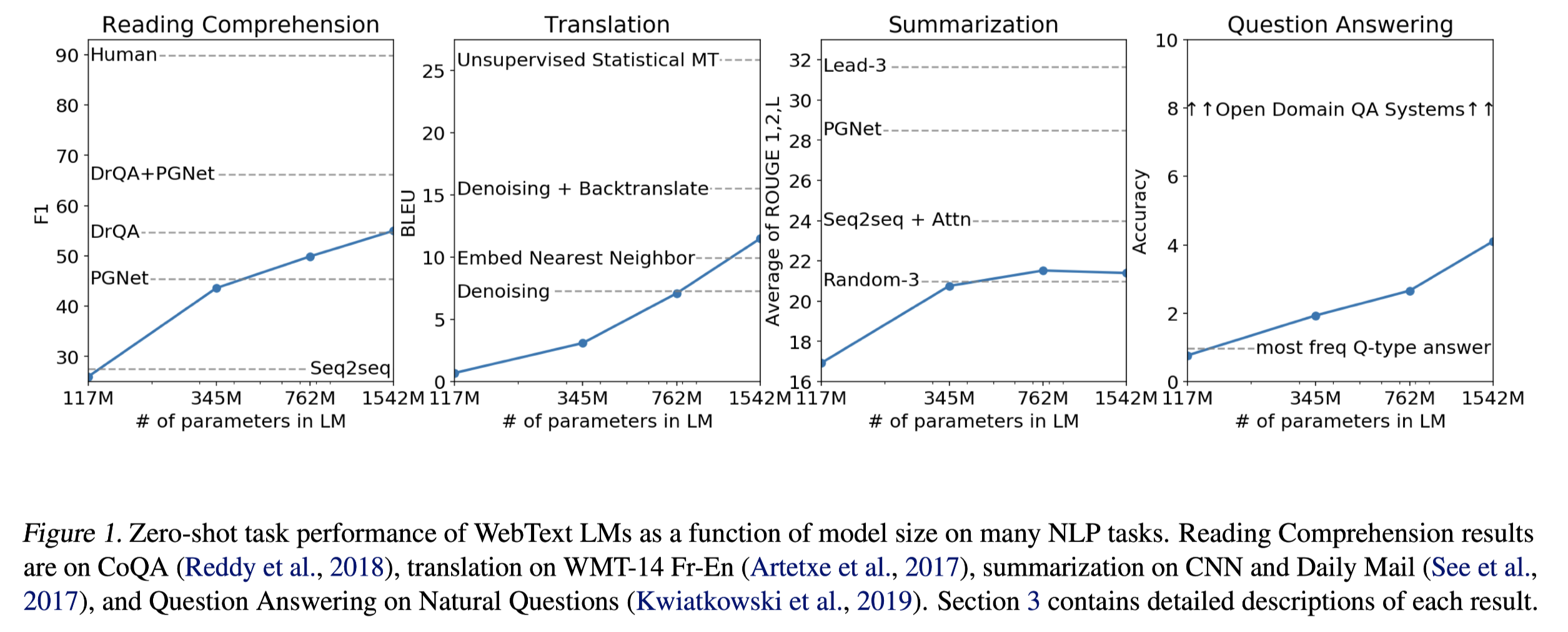
It can be seen that first 3 tasks, the results are not the best yet not the worst, however, the performance on Question Answering is bad, and other works perform way better than GPT-2.
But this is not over, because in the figure, there is still room for performance improvement on all 4 tasks as the size of the larger model increases. So here comes GPT-3.
GPT-3
The value of an article depends on the topic, effectiveness and novelty. GPT-2 has rather low effectiveness but strong novelty. As a result, GPT-3 aims to promote the effectiveness of its predecessor, while loosing the zero-shot condition to few-shot condition.
Abstract
The parameters of GPT-3 are enlarged 10 times to 175 billion. When applying GPT-3 to downstream tasks, strong performance is achieved without gradient update or fine-tuning. Besides, GPT-3 is capable of generating articles that are indistinguishable from humans' work.
Besides, unlikely to former papers, this is a 63-page technic report. Without limitation of words or page number, it is very detailed, especially for the experiment and discussion sections.
Introduction
There are 3 problems of current pre-training + fine-tuning language model:
- A large labeled dataset is still needed for a good result
- The pre-training model is not really generalisable because of the need for fine-tuning
- Human doesn't need large fine tuning dataset
When introducing their work, the authors try to re-define the concept of "meta-learning" and "in-context learning". What they really mean are training a huge generalisable model and train without updating the gradient, respectively.
Then 3 evaluation methods are presented:
Few-shot learning: 10-100 task-related data
One-shot learning
Zero-short learning
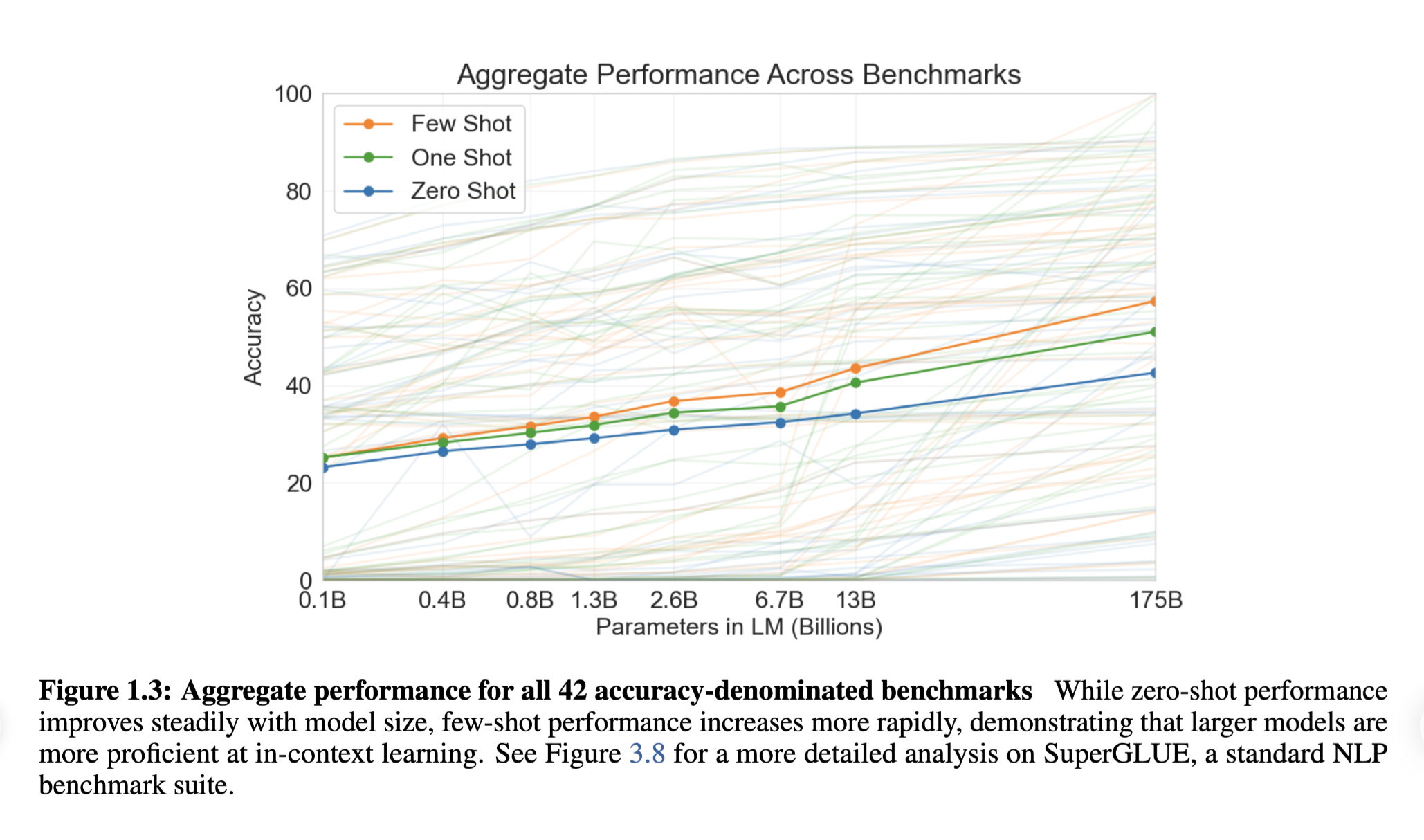
And the performance with model size is plotted below (1.3B matches the GPT-2 model). Can be seen the final accuracy (few shot - 175B) almost doubled the former GPT-2 accuracy (1.3B zero-short)
Approach
In this section, fine-tuning, few-shot, one-shot, zero-shot learning are explained first in this figure below:
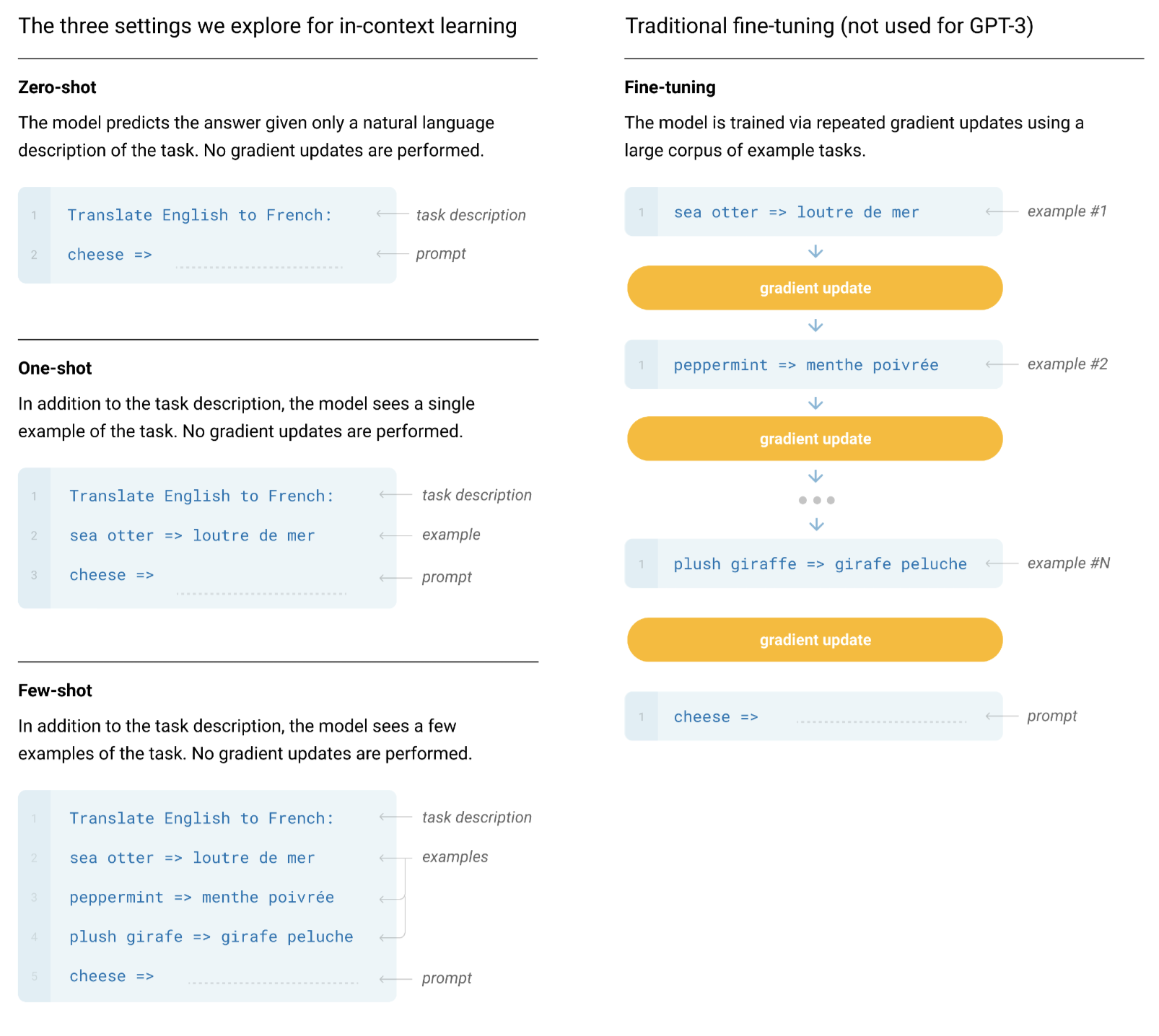
The right column denotes the traditional fine-tuning process that requires extra few gradient update steps. The left side shows how GPT-3 applies "in-context learning" during inference. Basically, the input is divided by 3 parts, task description, example, and prompt. The task description and prompt are ended by ":", and "=>" respectively. The Transformer Decoder extracts the features of the "context" and then predicts the next several words starting from the prompt. As a result, the model is able to infer without gradient updates. Yet it comes 2 problems with few-shot:
- Unable to process really long examples. For example, thousands of English-French translation dataset is easy to get access but they can rarely be leveraged to promote the model performance.
- The inference is one-time thing, meaning the model can't actually learn from previous task description or example. Same samples have to be inputed again an again.
As a result, the few-shot learning is not commonly used.
Model and Architectures
GPT-3 uses the same architecture as GPT-2 yet uses the methods form "Sparse Transformer" to modify the layers. And 8 different size of models are developed.
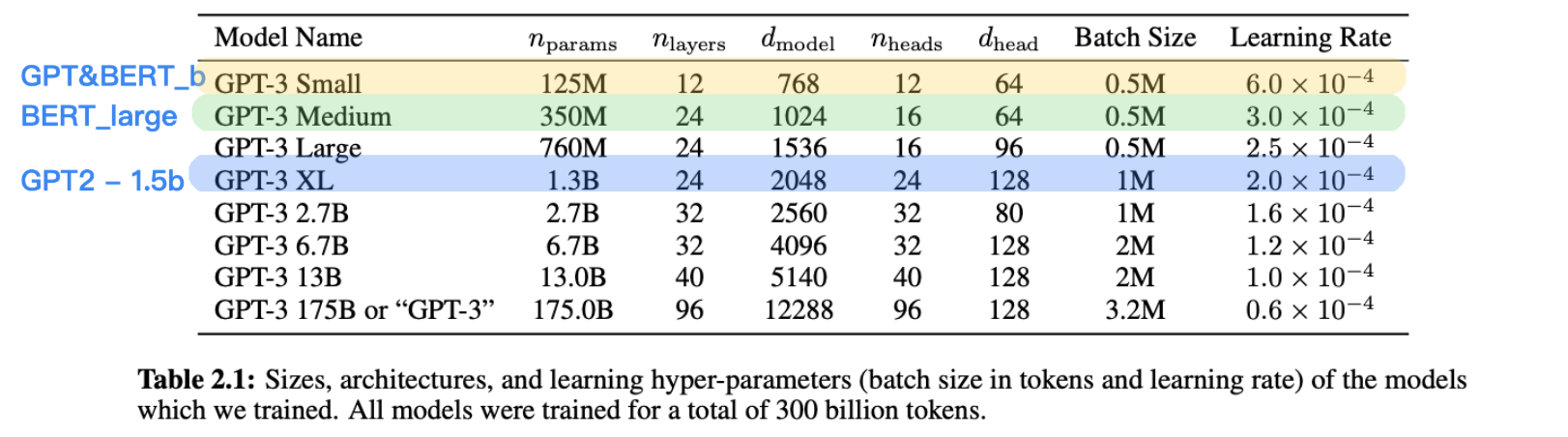
Yet compared with previous models, GPT-3 is "fatter" ,meaning with same dmodel (192x of GPT3small), nlayers is smaller (only 8x of GPT3small).
The mini-batch size goes up to 3.2M, definitely not mini. Large batch size improves the computational performance and parallelism while reducing the noise in each batch and making the model easier to overfitting. However, this defect is not evident in GPT-3. It is still an open question, now people consider it from two aspects: (1) the internal structure prevents the model from overfitting. (2) Such a large model is able to search for large space and it is more prone to converge to a simpler architecture.
The learning rate decreases with batch size increasing according to research1 and research2, also counter-intuitive. Former work shows that batch size should increase linear with the learning rate.
Training Dataset
With a huge model, Common Craw dataset has come back as an option. The authors clean this dataset in 3 steps:
- A logistic classification model is built, taking samples of Common Craw dataset as negative and WebText as positive. Such model is used on the whole dataset of Common Craw to predict positive (high quality) or negative. The positive stay and the negative are filtered.
- LSH algorithm is applied on the remaining dataset to filter the similar content.
- More "clean" datasets are mixed in with weight.
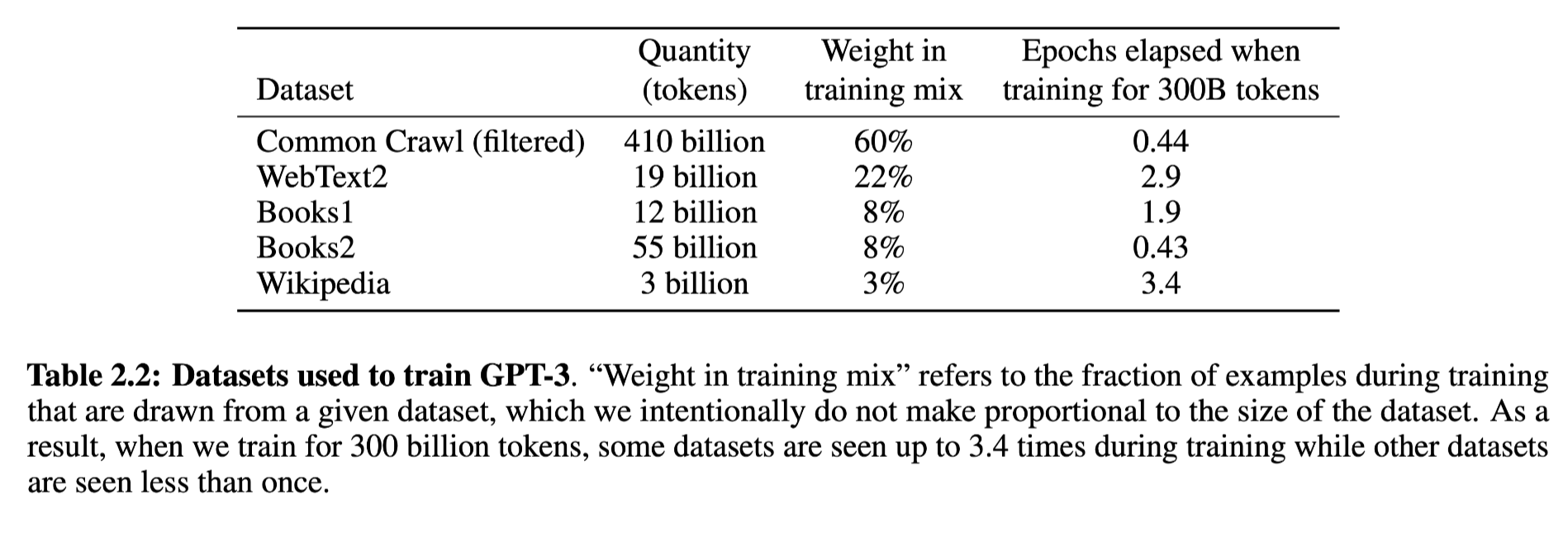
Training Process
Specific training details are not presented. Information so far is DGX-1 cluster is used.
Results
The results are too many so only interesting figures are covered.
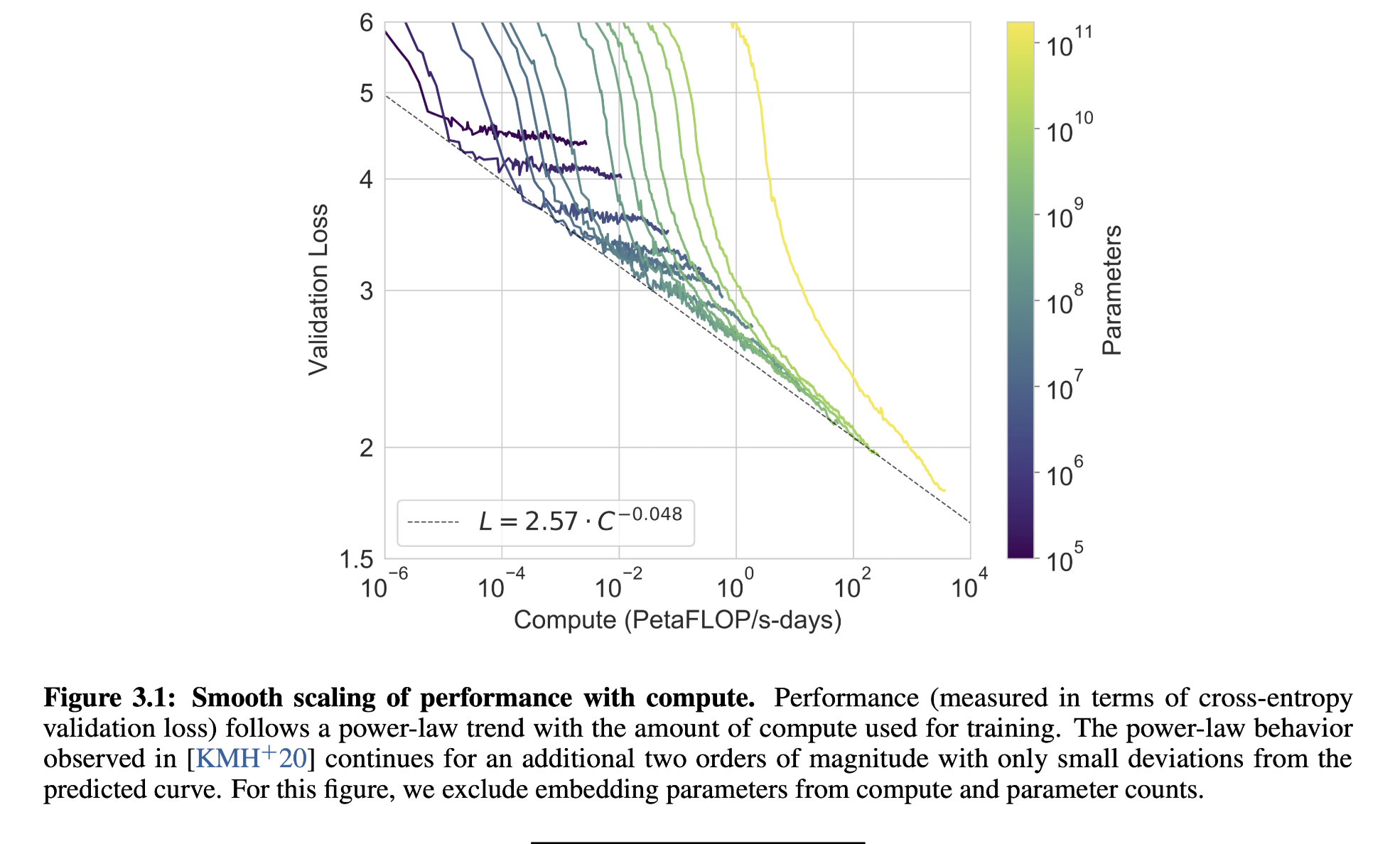
From the figure, the power law distribution of performance with compute are found, i.e. in order to decrease the validation loss linearly, the FLOPS need to increase exponentially. This still is a major problem in Machine Learning.
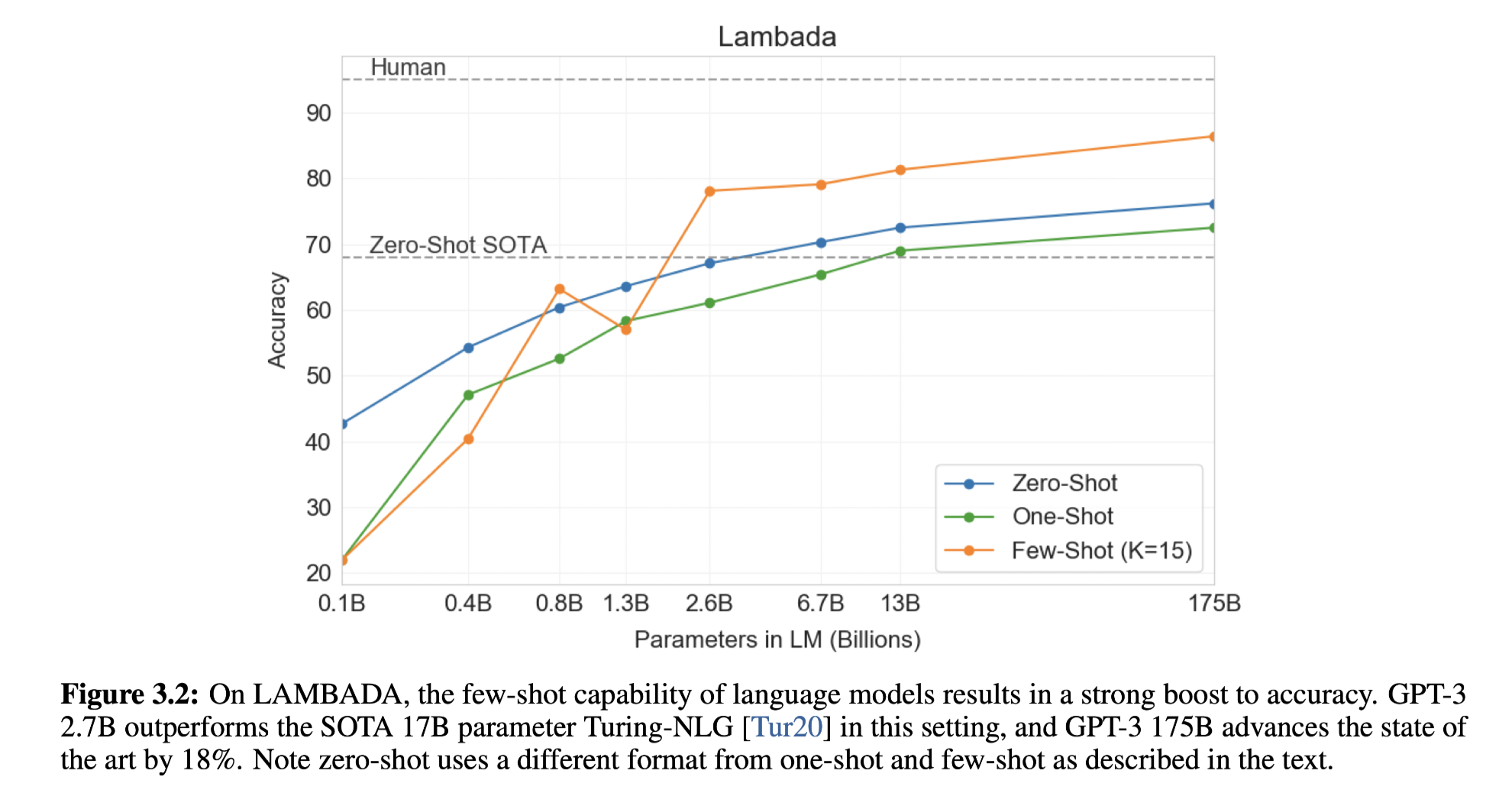
This figure shows the compression of results with Zero-shot SOTO and human. Nothing to comment. Just ... good.
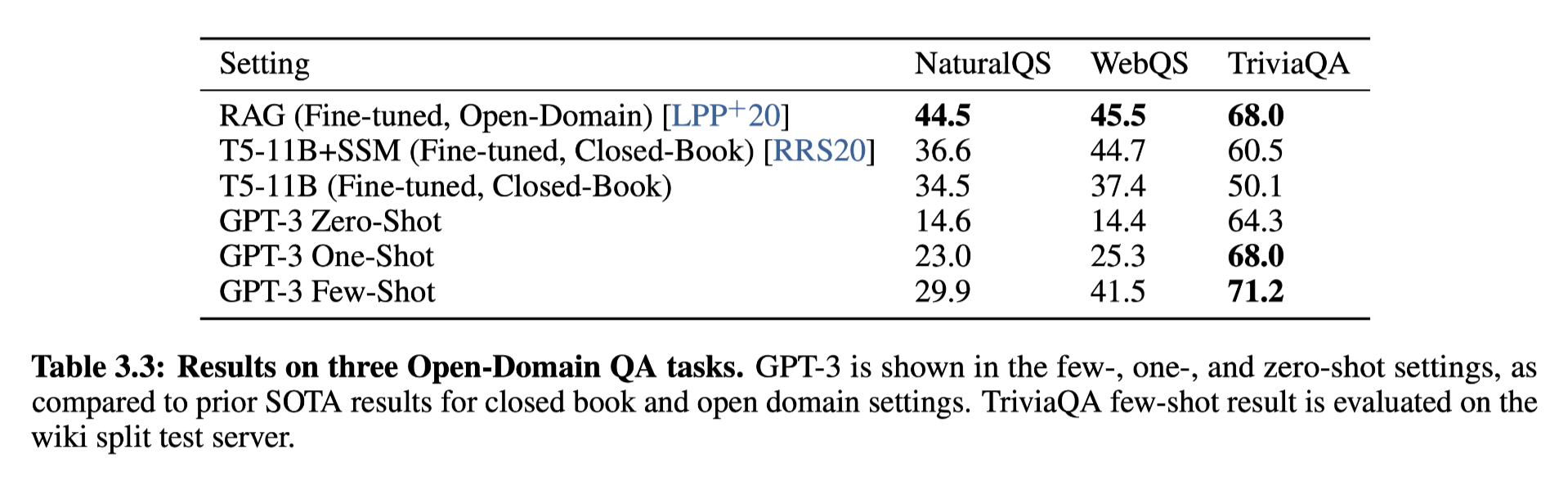 And on the Open-Domain QA tasks, GPT-3 outperform other models such as google T5. Google T5 can be considered as a model with both encoder and decoder.
And on the Open-Domain QA tasks, GPT-3 outperform other models such as google T5. Google T5 can be considered as a model with both encoder and decoder.
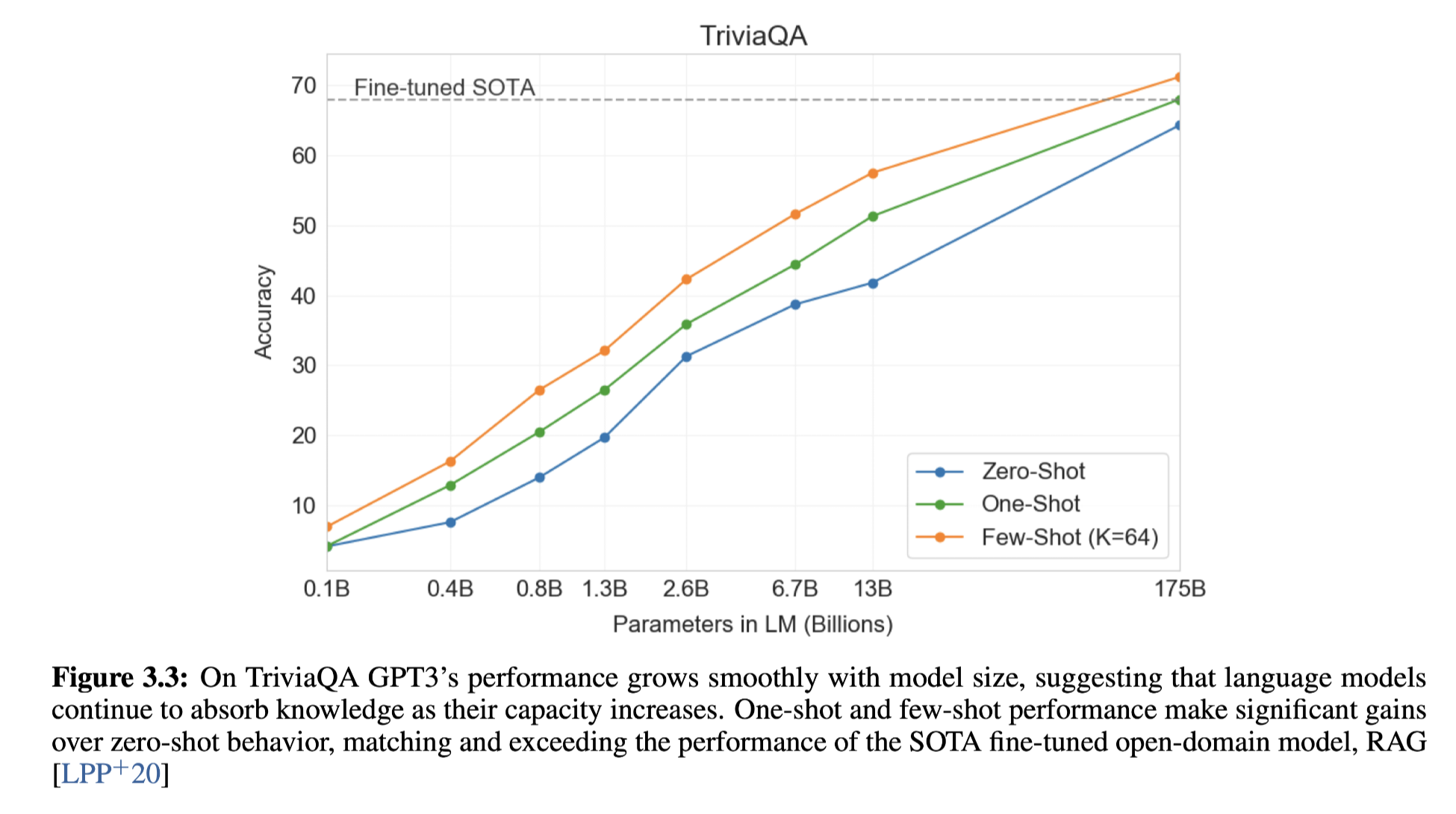
And few shot learning outperform SOTO fine tuning models.

In the machine translation task, it is interesting to see that other language to English is better than English to others.

Then a news article is generated with GPT-3 with numbers, years and time that makes the article look legit.
Limitations
- Text synthesis, the predicted texts are always looping.
- The bidirectional limit still exist because of the decoder structure.
- The tokens that learned by GPT3 are equally weighted, yet wasting the model on the meaningless but high frequent function words.
- No experience in Videos or real-world physical interaction.
- The interpretation is still low. It's nearly impossible to know how does such a big model works.
Broader Impact
- Can be used for fraud and crimes
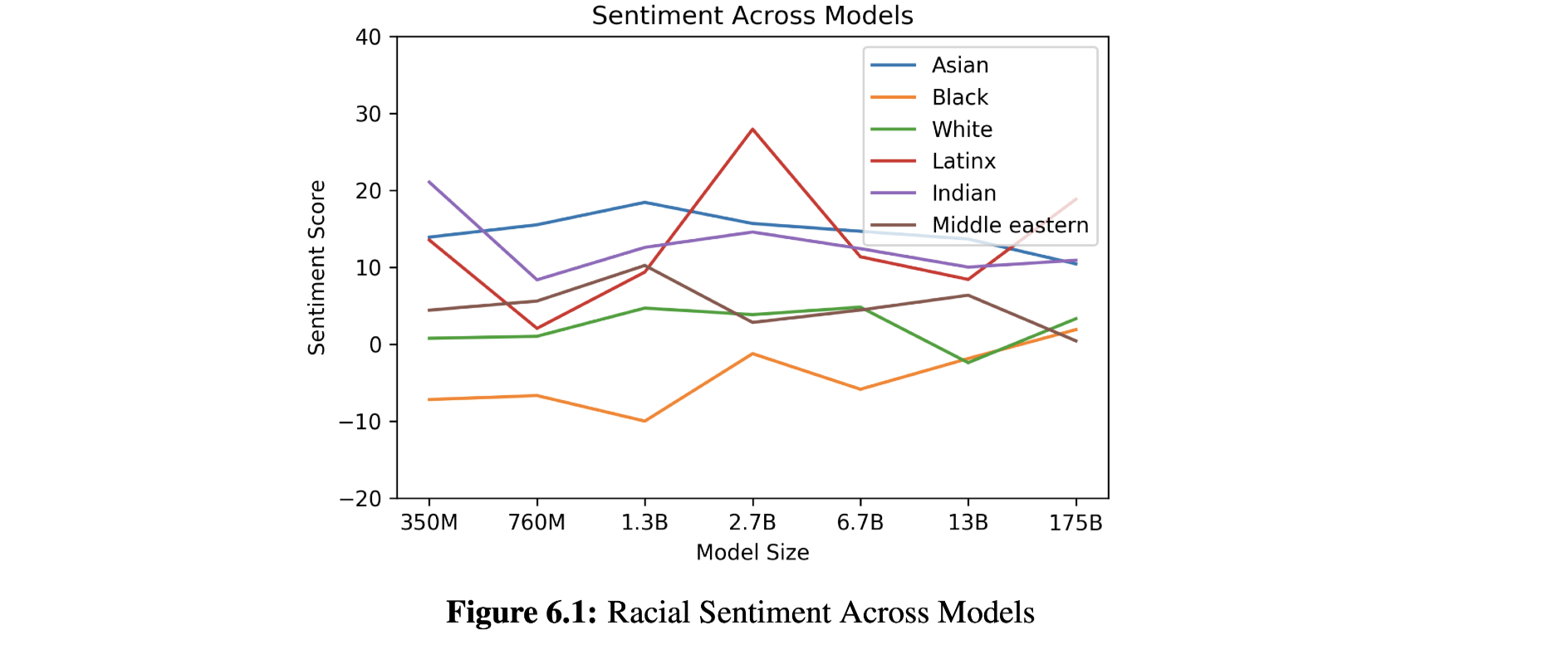
- Gender difference and race
- Energy consuming