Transformer
The transformer is the most important achievement in the last 5 years. It presents the fourth class of deep learning models besides MLP, CNN and RNN. And had a huge impact on the entire deep learning field, be it NLP or CV. Even the way the paper and network are named leads a trend.
This is a series of paper reading notes, hopefully, to push me to read paper casually and to leave some record of what I've learned.
Paper link: Attention is all you need
Useful link: https://www.bilibili.com/video/BV1pu411o7BE
Notes by sections
0. Abstract
According to the abstract, this work is first presented in the small field of machine translation, but because of the strong ability of generalisation. The transformer architecture has been extended in other fields such as CV and video.
6. Conclusion
In the last part of the conclusion section, the future of transformer is partly predicted by the authors, though most of these future work is done by other researchers.
1. Introduction
Firstly, traditional RNN, or GRU has been introduced. Then after a brief description of the sequential nature of RNN based models, the main problems of them are presented. That is, poor ability of parallelising, and poor long-range dependencies.
Later after the introduction of the attention framework and how to combine attention into RNN, transformer is presented.
2. Background
First, with the goal of gaining the ability to parallelise, the authors look back on using CNN for sequential data. With CNN, parallelising ability is in its nature and with multiple channels, multiple features can be learned through training. Likewise, the transformer is also parallelisable and Multi-Head Attention is designed with the ability to learn multiple features. But additionally the transformer is easier to learn dependencies between distant positions.
Afterwards, related work on self-attention and memory network is mentioned. And both the connections and distinctions with transformer are elaborated.
3. Model Architecture
After introducing the basic idea of the encoder-decoder architecture, the key transformer architecture diagram is given. And each part of the model is briefly described. (The diagram in this blog below is not the original, but a combination of 3 diagrams in the paper.)
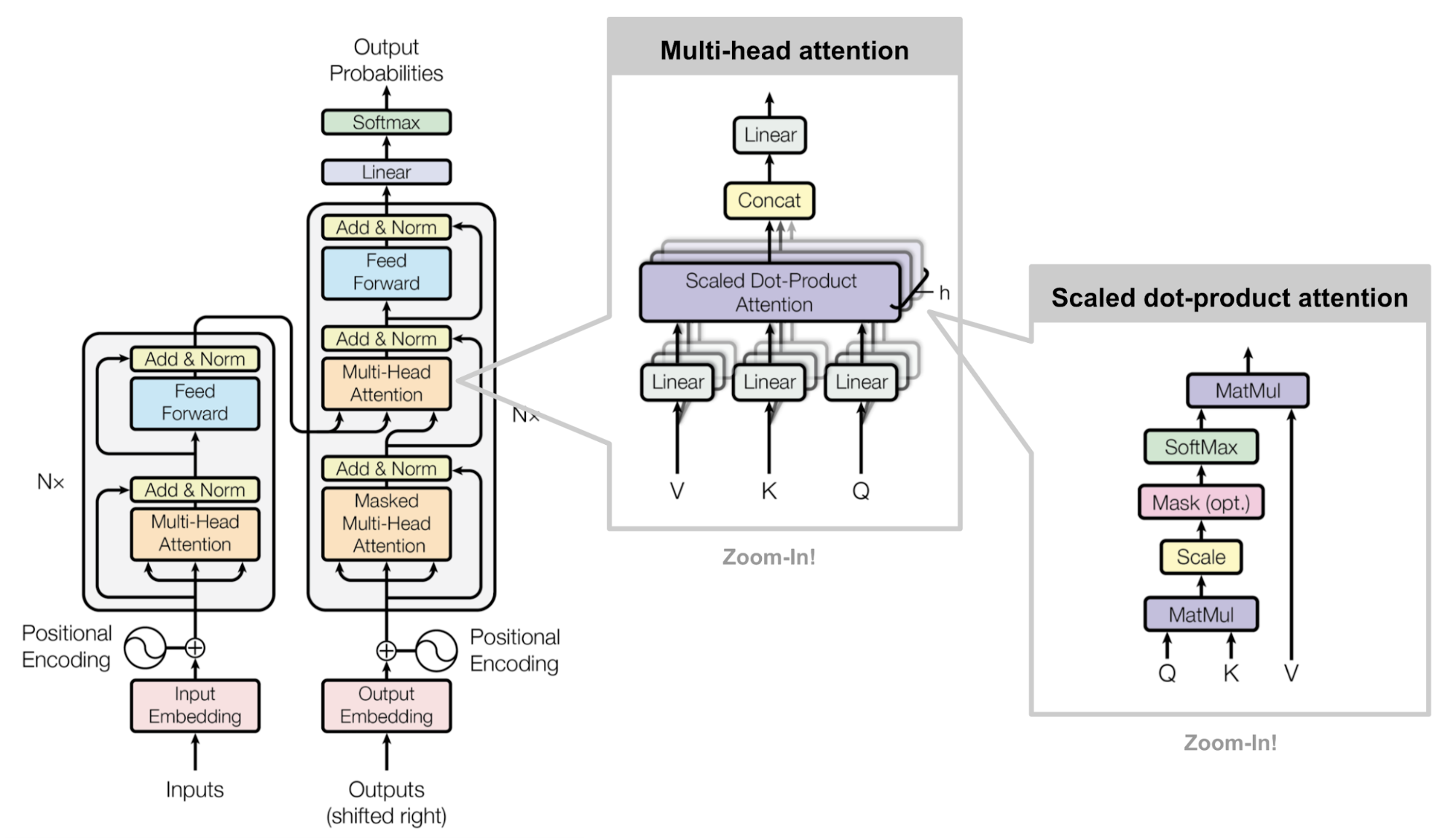
3.1 encoder decoder stacks
Encoder:
In addition to briefly describing the encoder architecture, the authors mention that in order to avoid the projection step on the residual connection layers, the same input and output dimension is chosen in each sublayer, which is different from what CNN normally does. And this simple design yields the super parameters of the encoder to 2: Nx - the number of the "encoder block" and d_model - the feature dimension of the output layers. And this design makes the follow-up work such as bert, GPT-3 simple as well.
Here is one thing that has been ignored: the definition of layer norm.
Unlike batch normalization, Layer Normalization directly estimates the normalization statistics from the summed inputs to the neurons within a hidden layer so the normalization does not introduce any new dependencies between training cases.
More is on https://paperswithcode.com/method/layer-normalization
Decoder:
Because in the prediction mode, the decoder is self-regressing, meaning that when predict y_t, only x_0 to x_t are available. However, the self-attention layer is able to attend to all the data i.e. x_0 - x_n. To prevent this, a masked multi-head attention layer is introduced so that when predict y_t, x_t+1 - x_n are masked.
3.2 Attention
Similarly, after running over the definition of attention mechanism, the 2 modifications: scaled dot-product attention and
Multi-head attention are described.
As we all known, there are two methods (attention scoring functions) of calculating the similarity of query and key(attention weights over the value). One is additive attention. It is complex but allows different length of key (dk) and query (qk). And Additive attention layer includes learnable parameters that can be tuned during training. Another one is dot-product attention, it is simply dot product of the transverse query and key matrix. It requires same length of query and key and no learnable parameters are introduced.
scaled dot-product attention
It pretty much is the dot-product attention multiply with a scaling factor of 1/√dk. And it is because for large dk, the deviation of the dot-product results might get too large, and the according gradient can get extremely small and hard to train.
But look the figure 2 of the paper, an optional mask node is shown in the computation graph. And the algorithm of mask is not described in detail. Basically when calculating q_t, in the mask node, the attention scores a_t+1 - a_t are substituted to a huge negative so that after softmax, the attention weight is 0 on values v_t+1 to v_n. And it is corresponding to the how the decoder works in the prediction mode.
multi-head attention
How mutli-head works is introducing clearly in the paper:
linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values
The question is why doing that. First, no learnable parameters in the dot-product attention, and second, to mimic the CNN extracting the features from different perspectives.
Applications of Attention in our Model
It is well shown on the whole architecture figure. In the figure it consists of 2 self-attention block and 1 attention block, where key-value is from the encoder and query is from the decoder.
3.3 Position-wise feed-forward networks
It is a simply an MLP with one hidden layer. And the hidden size is 4 times of the input and output size.
3.4 Embedding and softmax
One point is they multiply the weights by√d_model. And first same reason with before, and second, with scaled weights, the scale matches the scale of positional encoding described below.
3.5 Positional Encoding
Different with RNN, transformer architecture reads no sequence information. And the authors add the positional information in the input data.
4 Why Self-Attention
Basically it explains the table 1 below:

It might be the case but it's not been accepted by some researchers. And the restricted self-attention is rarely used. The table shows that if n and d are the same, self-attention, RNN, and CNN possess the same complexity per layer, but self-attention outperforms them on the sequential operations and the max path length. But actually, a huge mount of layers and parameters and data are required for a self-attention model achieving a similar result as RNN and CNN. And nowadays all models based on the transformer are very expensive.
6 Results
6.2 Model Variations
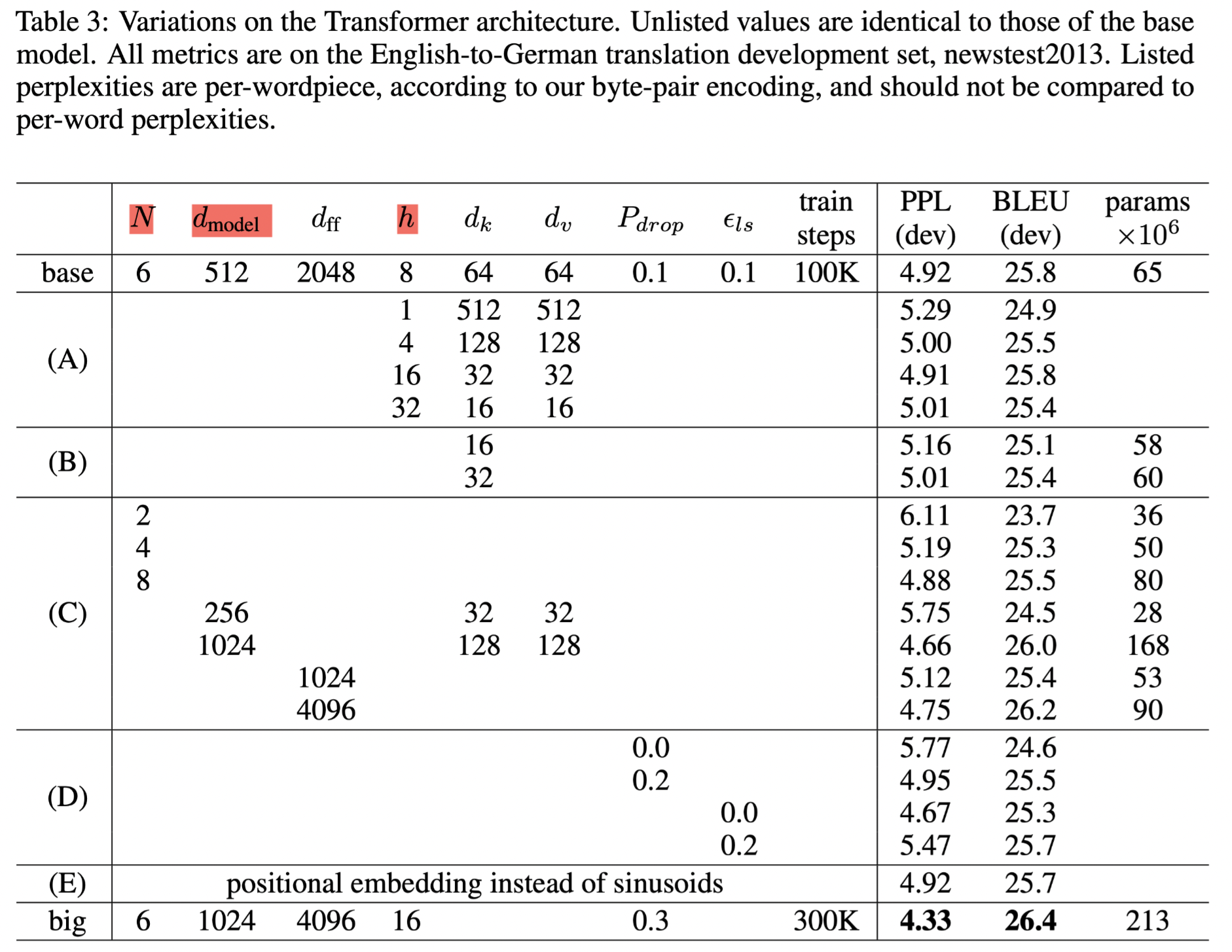
From Table 3, we can see the hyper parameters are not so much, and this simple design benefits the follow-ups. For example Bert and GPT.
Reviews
Writing: It is concise and neat. But if the possible, it's better to describe why of doing it, and show more thoughts on the model to make the paper "deeper".
Model: Transformer change the NLP filed just like how CNN change the CV filed. Through after transformer based model such as BERT, it is possible to pretrain a huge model to rise all the NLP performance. Besides, in other fields such as CV and audio, transformer becomes a great rising point. And the fact that transformer may suitable for all the deep learning tasks gives a new thought of muti-model learning. Maybe a general model able to extracting video, pictures, audio into a same semetic space is coming soon.
Yet, despite the great experiment performance, we still can't fully understand why transformer works. For example,
attention is not all one need, because the residual connection and MLP are all critical. We still don't know why.
Why without explicitly model the sequence or the space, transformer outperform RNN and CNN. One explanation is that it is because transformer's inductive bias is more relaxed than either recurrent or convolutional architectures. And that is why huge amount of data are needed for transformer to achieve a good result.