ResNet
Since its introduction in 2015, ResNet and its variants have accounted for 50% of deep neural networks in use. The idea of "Residual" has been proved to be efficient and important to deep NN.
This is a series of paper reading notes, hopefully, to push me to read paper casually and to leave some record of what I've learned.
paper link: Deep residual learning for image recognition
useful link: https://www.bilibili.com/video/BV1Fb4y1h73E
Notes by sections
0. Abstract
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset
Not only the 1st place results on several tasks but the potential to train a 1000-layer network made this Residual framework a huge attention.
Unfortunately, due to the 8-page limitation of CDPR, and the massive number of results to be presented, there is no room for the conclusion section in this paper.
Key figure
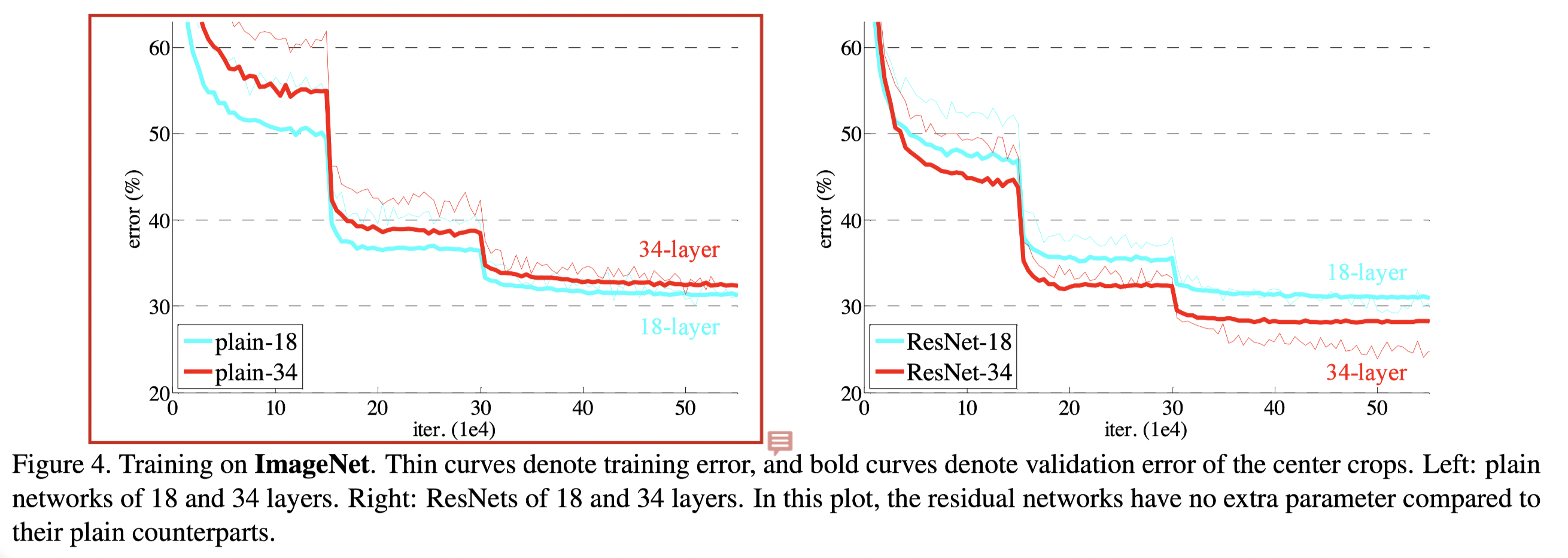
This is the key figure showing that the degradation in accuracy caused by the depth in plain networks has been well addressed in ResNet.
1. Introduction
This section first presents the need of training deeper neural network. And the first obstacle that encountered during this process is non-convergence cause by gradient vanishing / explosion, and it has been well addressed by normalised initialisation and intermediate normalisation layers.
And the main focus of this paper is the second obstacle i.e. deeper networks have difficulty converging to lower losses and may perform worse than networks with fewer layers. And they addressed this obstacle by introducing the Residual learning framework as shown in the pic below. And this framework is easy to implement in caffe, the most popular DL framework back to 2015.
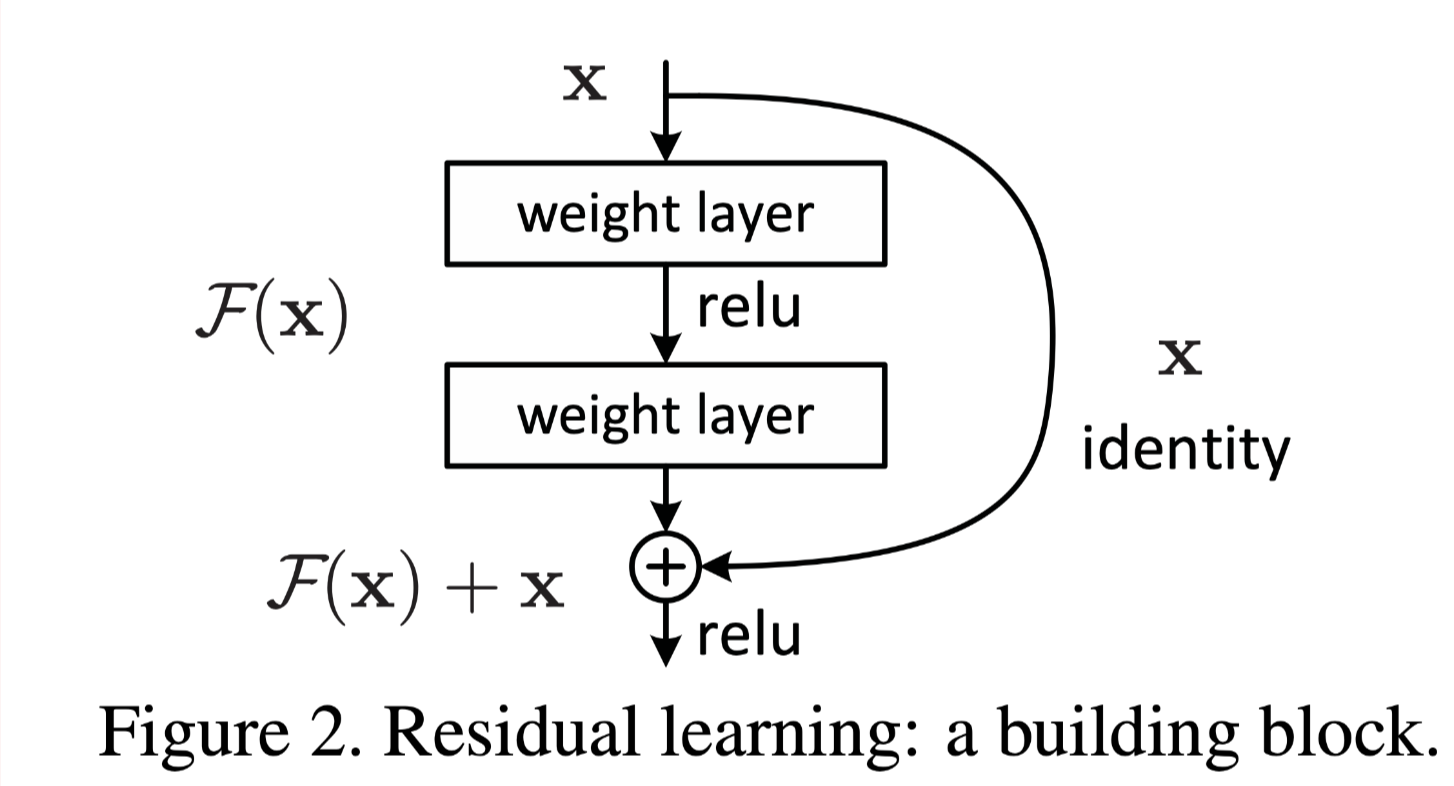
Afterwards experiments results are briefly mentioned. The introduction section played as an expanded version of the abstract and the residual method is mainly focused, which is helpful for readers to catch the essence of the whole paper.
2. Related work
Residual representation
Actually the concept of residual is more common in the fields of statistics and machine learning. For example in linear regression, the residual denotes the distance between the estimated and the actual results (residual=y- y ̂ in 2D). And the iterative process of calculating the regression line aims to minimise the mean square of the residual loss. In addition, the well-known GB gradient boosting algorithm for machine learning is also based on the residual loss.
Because this paper mainly focus on computer vision, so these early work isn't included.
Shortcut connections
It looks like this paper combines these two well-studied approaches with amazing results. First ideas are not necessary to make a paper a classic. Just like the quote on the Google Scholar homepage: stand on the shoulders of giants.
3. Deep Residual Learning
Let us consider H(x) as an underlying mapping to be fit by a few stacked layers (not necessarily the entire net), with x denoting the inputs to the first of these layers.
First is the meaning of H(x), underlying mapping is actually intuitive but it confused me for a while, so here's the answer below:
What does the phrase 'underlying mapping' mean? - Data Science Stack
Functions map domains to ranges. Neural networks learn such functions, so you can think of a neural network as a mapping of input spaces to output spaces. Deep neural networks are stacked with many layers of course, and each of those can be viewed as sub-functions of the network with their own underlying mappings. For example, each layer in a convolution network consists of some convolution layers + some other helper layers such as normalisation and pooling.
Next the paper brings up 2 methods to address the shape difference between X the input and H(x) the output for one particular layer that may occur. Option (A): 0 padding and Option (B): 1*1 convolution to project the channel and pooling with stride to adjust the height and width.
4. Experiments
Identity vs. Projection Shortcuts

After introducing the well known architectures, the 2 methods to address the shape difference are also studied. 3 groups are studies, Option (A): 0 padding, Option (B): projection when necessary, Option (C): projection to all layers. And because of the increasing of parameters caused by the projection, it is not surprise to discover C is better than B than A. And Option (B) is the winner considering both the performance and the efficiency.
Deeper Bottleneck Architectures

In ResNet18 and ResNet 34, the standard architecture is fine. But for deeper network, in order to decrease the flops, the bottleneck architectures is deployed. Basically in each residual block, decreasing the number of channel by 1*1 convolution first then expend the channel back to the number of input channel. As can be seen in Table 1, the flops of ResNet34 is similar to that in ResNet50. But this is only theory, in practice ResNet50 is obviously more expensive because of the inefficiency of computing 1*1 conv.

Exploring Over 1000 layers
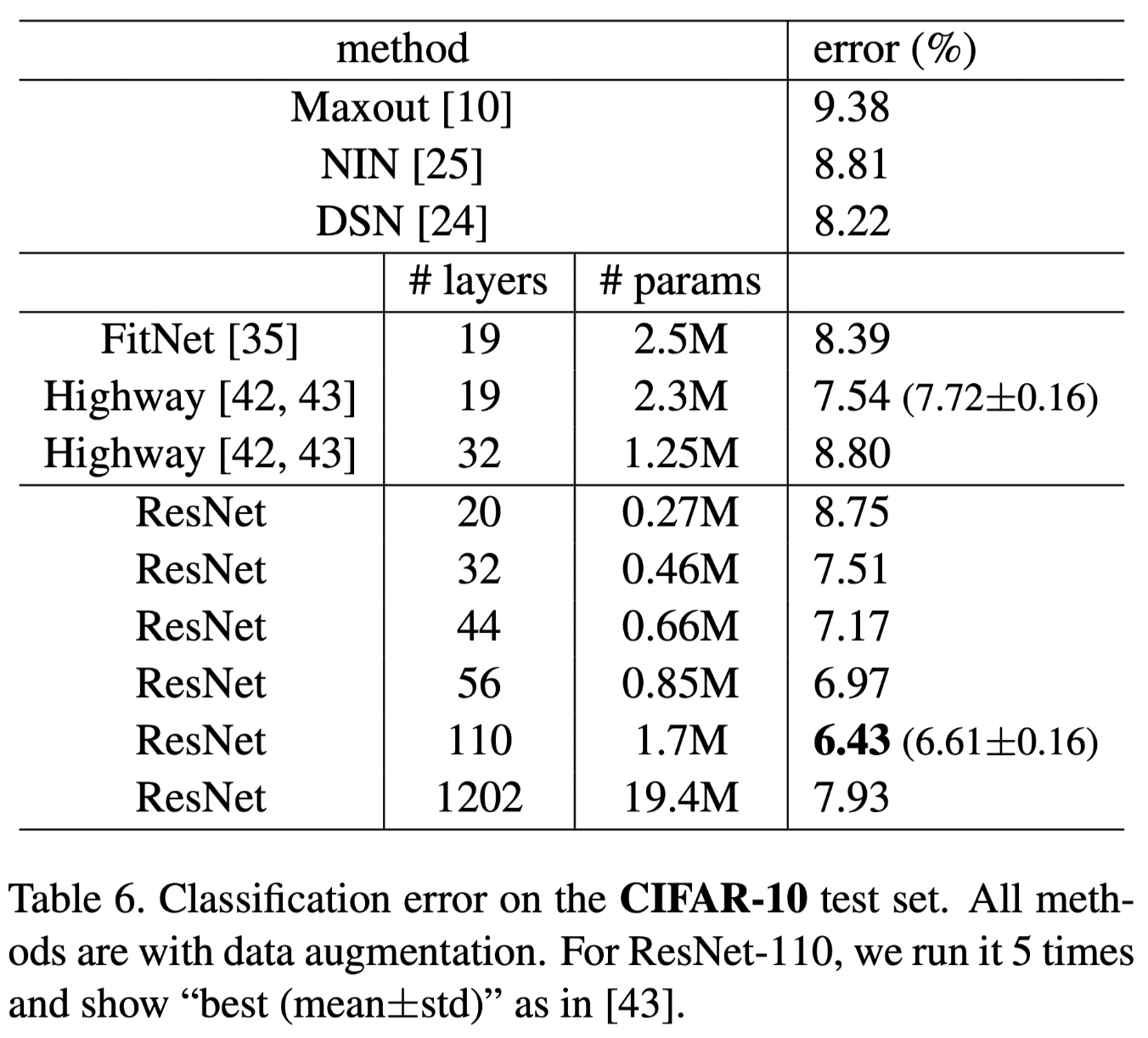
Networks with layer numbers from 20 to 1202 are applied on dataset CIFAR-10 (With only output size 32*32 compared with >300*300 on ImageNet, the networks are slightly modified). And the results shows that even with an aggressive depth on a tiny dataset, no difficulty of optimisation occurs. Yet shown on Table6, the test set classification error goes up compared with the shallower models because of the overfitting.
Some Reviews
This is a model with relatively simple idea and the authors have a great writing skill to make this paper neat and clear.
The main contribution of this paper is introducing the residual block and skipping connection in deep learning.
Although the authors intuitively explain and provide some experiments, the explanation is not currently accepted by the mainstream. Today, the reason why ResNet can achieve better results than ordinary networks is mainly because of its property of preventing vanishing gradients. The ordinary network without the residual framework cannot be trained in the later stage of training.
It's still an open question why the 1000-layer network has low level of overfitting on a simple dataset. The same question is good performance on large networks such as the transformer series. One explanation is that despite the large network size, the intrinsic model complexity is low.